Case Study
1. Introduction
1.1. What is Armada?
Armada is an open-source container orchestration tool that allows administrators to automate the configuration and deployment of development environments in the cloud.
Each development environment within Armada exists as a set of containers that exposes an Integrated Development Environment (IDE) and all its necessary dependencies to developers via their browsers. Armada's architecture is self-hosted on an administrator's Amazon Web Services (AWS) account and is entirely managed from a dashboard in the browser.
1.2 Understanding the Problem Space
Before diving into Armada's feature set, it's important to highlight the difficulties of setting up and maintaining developer environments. Common challenges include configuration, dependency management, and resource availability.
1.2.1 Configuration Overload
Developers have no shortage of productivity-enhancing tools from bundlers to compilers to linters to transpilers. These tools support a diverse set of use cases across an ever-expanding number of disciplines, often exposing a configuration file for users to fine-tune settings.
While the flexibility of customizing a tool to address individual use cases may seem like an ideal solution, repeating this process across multiple tools can lead to a constellation of fragile dependencies and lengthen the amount of time that it takes to get started on a project. Furthermore, some tools offer so much flexibility that their configuration files can require their own specialists to decipher, all of which can easily lead to decision fatigue. Rather than outlining your core feature set, you'll spend a non-trivial amount of time level-setting your linter and fiddling with your formatter.
1.2.2 Dependency Management
Most applications rely on other publically-available tools, frameworks, and libraries. Reusing the work of others removes redundancy from workflows and greatly accelerates the speed with which software can be developed. However, using these tools comes with its own set of tradeoffs.
Almost all modern software is constructed in this way, which means that any project that an engineer might work on will have to contend not only with its immediate dependencies but also the dependencies that its dependencies introduce. While package management tools abstract much of this complexity away, developers are still left to deal with the fragility that arises from long chains of dependencies: upgrading a single dependency can break the entire chain or create a circular dependency.
1.2.3 Resource Availability
Depending on the environment you're working in or the type of application you're attempting to construct, your workflow may require a significant amount of computational resources (i.e., CPU, RAM, GPU, etc.).
Such tasks include:
- Creating virtual environments on your local machine (i.e., VMWare, Docker, etc.).
- Utilizing compilers and test runners in "watch" mode.
- Running emulation software for specific deployment targets (i.e., Android, iOS,watchOS, etc.).
- Compiling complex or large applications.
- Running one or more databases.
These computationally-intensive tasks increase the minimum hardware requirements needed to be able to do certain kinds of development work. Unfortunately, this hardware can be expensive, limiting access to the machines that can perform these tasks.
1.3 Narrowing Our Focus: Education
Although these issues are commonplace, they're often most keenly felt by students just getting started, which means they're particularly challenging for their instructors as well.
1.3.1 Students
For students who are just learning how to build software, the challenges of setting up a development environment can be frustrating at best and insurmountable at worst. A new student's time and effort are better spent on gaining fluency and comfort with core programming skills, such as being able to write valid code, understand syntax, efficiently parse error messages, work on the command line, and read documentation. Furthermore, time and attention are both finite, and students who have exhausted their mental resources in the setup phase of a lesson are less likely to complete the lesson itself.

1.3.2 Instructors
From the perspective of those teaching software development, understanding precisely why a student's development environment isn't working correctly can be a time-consuming guessing game, and navigating version conflicts and configuration issues on a student-by-student basis is neither efficient nor scalable.

2. Supporting Students
2.1 One-by-One
In a typical classroom setting, each student's development environment is their local machine. When issues with dependencies or configuration arise, the instructor needs to troubleshoot them on the individual machines where they're appearing. In the best case, an issue may be so common that the instructor can document how to resolve the problem and leave said resolution to students. An alternative is that the instructor can manually intervene to prevent the issue from arising again. In any event, dealing with the recurring issues of configuration and dependency management across many individual machines is burdensome.

2.2 One for All, All for One
What if an instructor were able to guarantee that every student had access to the same hardware and software? Dealing with a single configuration would significantly reduce the complexity of supporting a group of students. But, how could this be done?
Rather than purchasing a new computer for every student, an instructor might consider virtualization: configuring multiple, isolated environments for students all from one server.
2.2.1 Virtualization
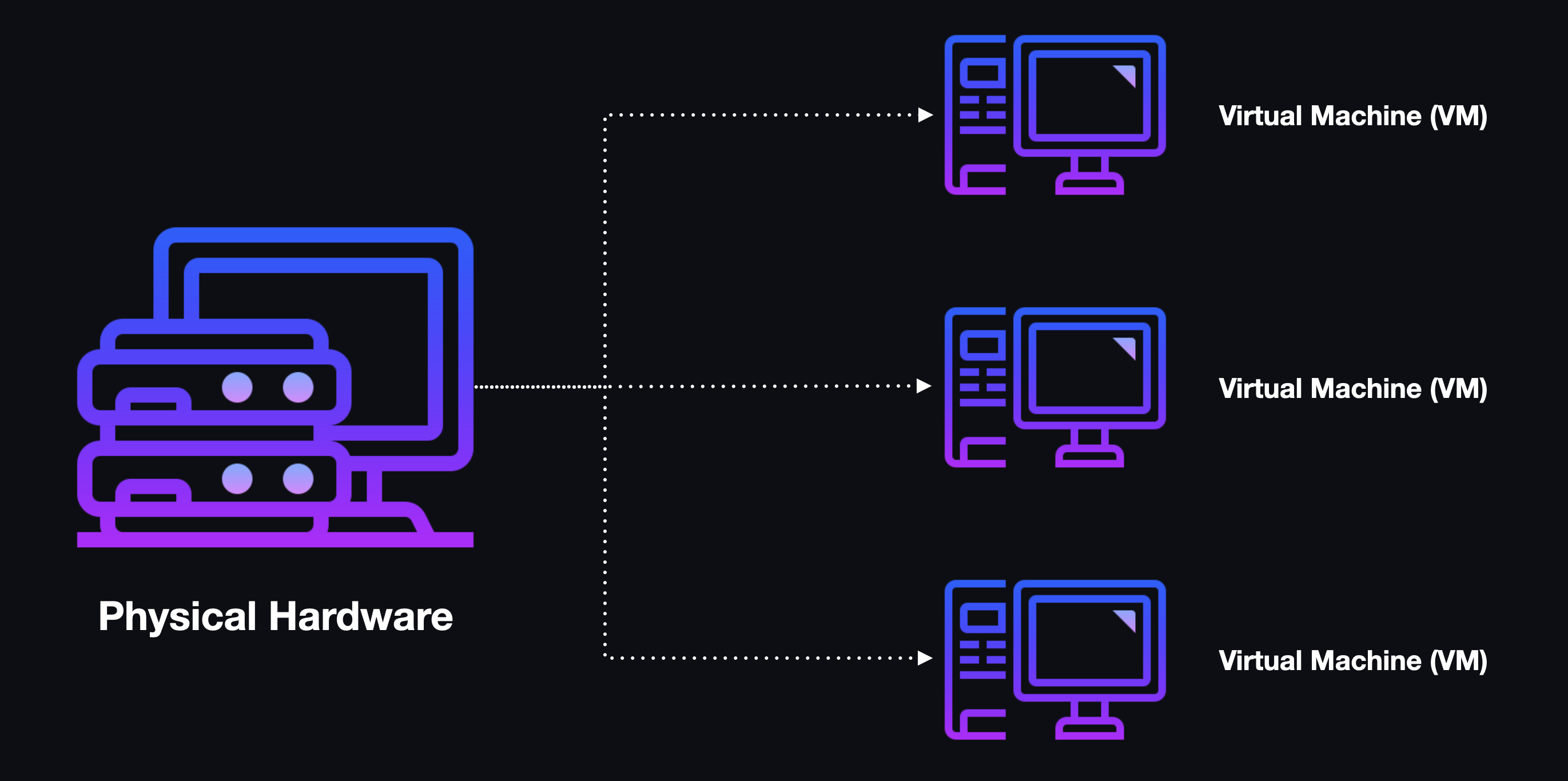
According to International Business Machines (IBM), "Virtualization uses software to create an abstraction layer over computer hardware that allows the hardware elements of a single computer—processors, memory, storage and more—to be divided into multiple virtual computers, commonly called virtual machines (VMs). Each VM runs its own operating system and behaves like an independent computer, even though it is running on just a portion of the actual underlying computer hardware." In some instances, the computer running the virtualized environments is referred to as the host or host machine, while the virtualized environments themselves are referred to as guests or guest operating systems.
2.2.2 The Upside
One of the key features of virtualization is the ability to create an image, a snapshot of a computer's operating system, its files, and its overall state. After an image is created, it can serve as the basis for an arbitrary number of virtual machines. For instance, an image could contain all of the prerequisite files, software, and dependencies needed to perform tasks for a given class. These images could also be used to restore a given virtual machine to the desired state should something go awry.
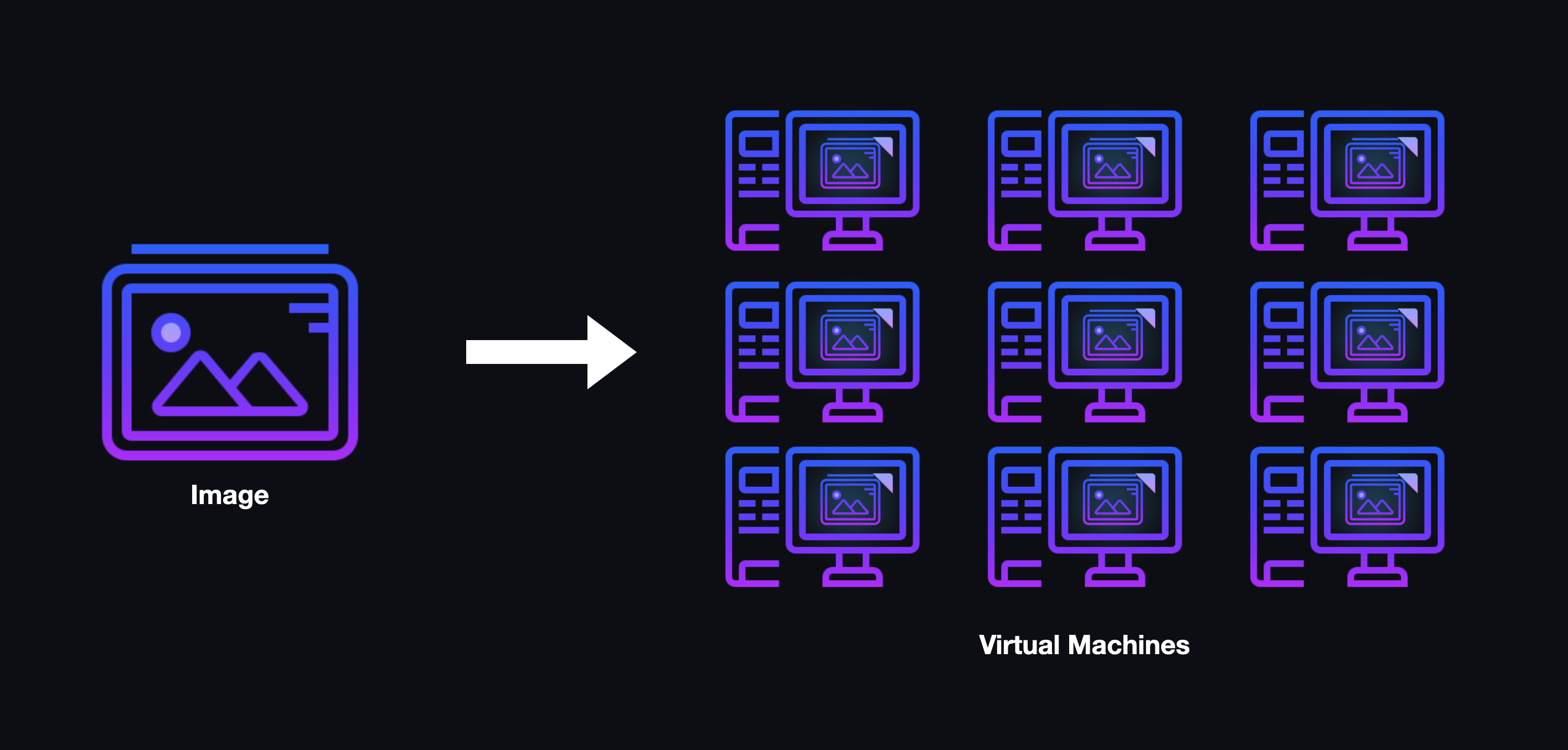
With this approach, an instructor could configure a single, functional workspace to distribute to each student. If changes or updates need to be made, the instructor could simply create a new image, ensuring that solving a configuration problem for a single student would solve the same configuration problem for all students.
2.2.3 The Downside
The prospective overhead in terms of time and money is significant. The kinds of servers capable of hosting enough VMs for a classroom of students are not cheap, and managing them becomes a job in and of itself. Additionally, this is not a scalable solution: adding capacity means upgrading existing hardware or purchasing new hardware altogether. The server is also a single point of failure. If it goes down, no student can access their environment.
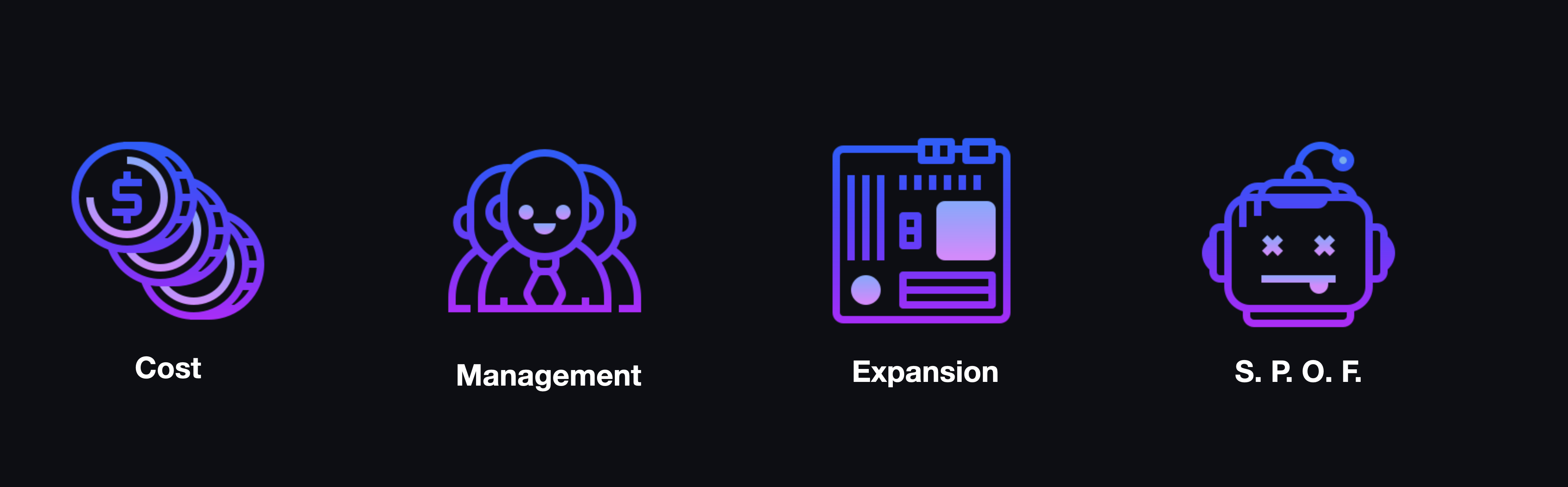
2.3 The Cloud: A Possible Solution
An ideal solution would abstract away the problems of hardware without being cost-prohibitive while ensuring that issues resolved for one student would be resolved for all students. Fortunately, modern cloud technologies make such a solution possible. By offering centrally-managed, virtualized environments to students from the cloud, it's possible to affordably offer a set of virtual machines that can be configured and maintained from a single template and served to an arbitrary number of students.
3. Cloud Deployments
3.1 What are Cloud Environments?
Cloud environments are a type of third-party service that provides on-demand access to networking and computational resources. Unlike on-premises data centers, which require purchasing and configuring new hardware to expand capacity, cloud environments can easily scale with demand. To add capacity in a cloud environment, users simply need to make a request to the cloud provider. In many cases, the provisioning of capacity can be managed automatically to adjust the number of resources according to the user's needs.
3.2 A Modular, Replicable Approach
In a cloud environment, instructors no longer have to concern themselves with hardware. They can dedicate their time and attention to configuring a single environment exactly as they want it before deploying it as many times as they need.
3.3 A Identifying Inefficiencies
This solution has a significant drawback, however, because the minimum memory and CPU capacity for VMs offered by cloud providers is still well beyond what most development environments require. Most of the time students won't use the full capacity of either the machine's CPU or its memory, which means that instructors are paying for more resources than they're actually using. For this reason, many developers opt to further virtualize their environments with the help of containers.

3.4 Containerization

Containers use virtualization but are not fully-fledged virtual machines on their own. Instead, containers are applications that are bundled along with their dependencies using software such as Docker.
Rather than virtualizing an entire machine including its hardware like a VM, containers instead virtualize the OS, allowing them to stay much lighter-weight than VMs & unaware of the underlying systems they are running on.
One side effect of this lighter-weight is that containers aren't meant to persist for long periods of time. Instead, they're designed to be created, used, and then destroyed. Due to their ephemeral nature, containers often present unique challenges when attempting to persist data.
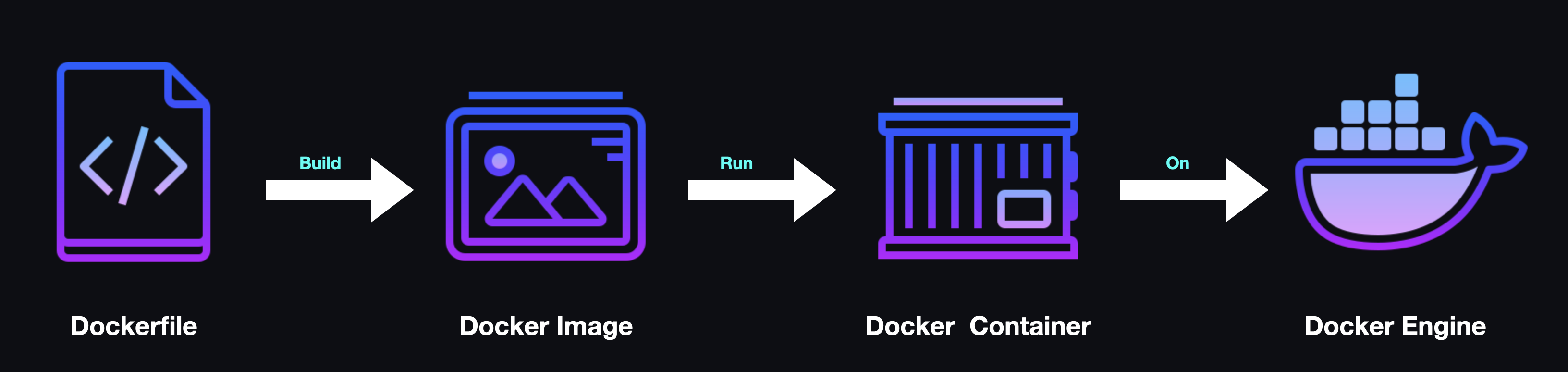
3.4.1 An Aside: Docker
Docker is an open-source platform for creating, developing, and managing containers. Within the Docker ecosystem, container images are created via a Dockerfile. Dockerfiles enable developers to configure how a container is constructed, including specifying a base image that can be extended. These images are consumed by the Docker Engine which is a runtime environment that enables containers to be run locally on a developer's machine.
3.5 The Challenges of Managing the Cloud
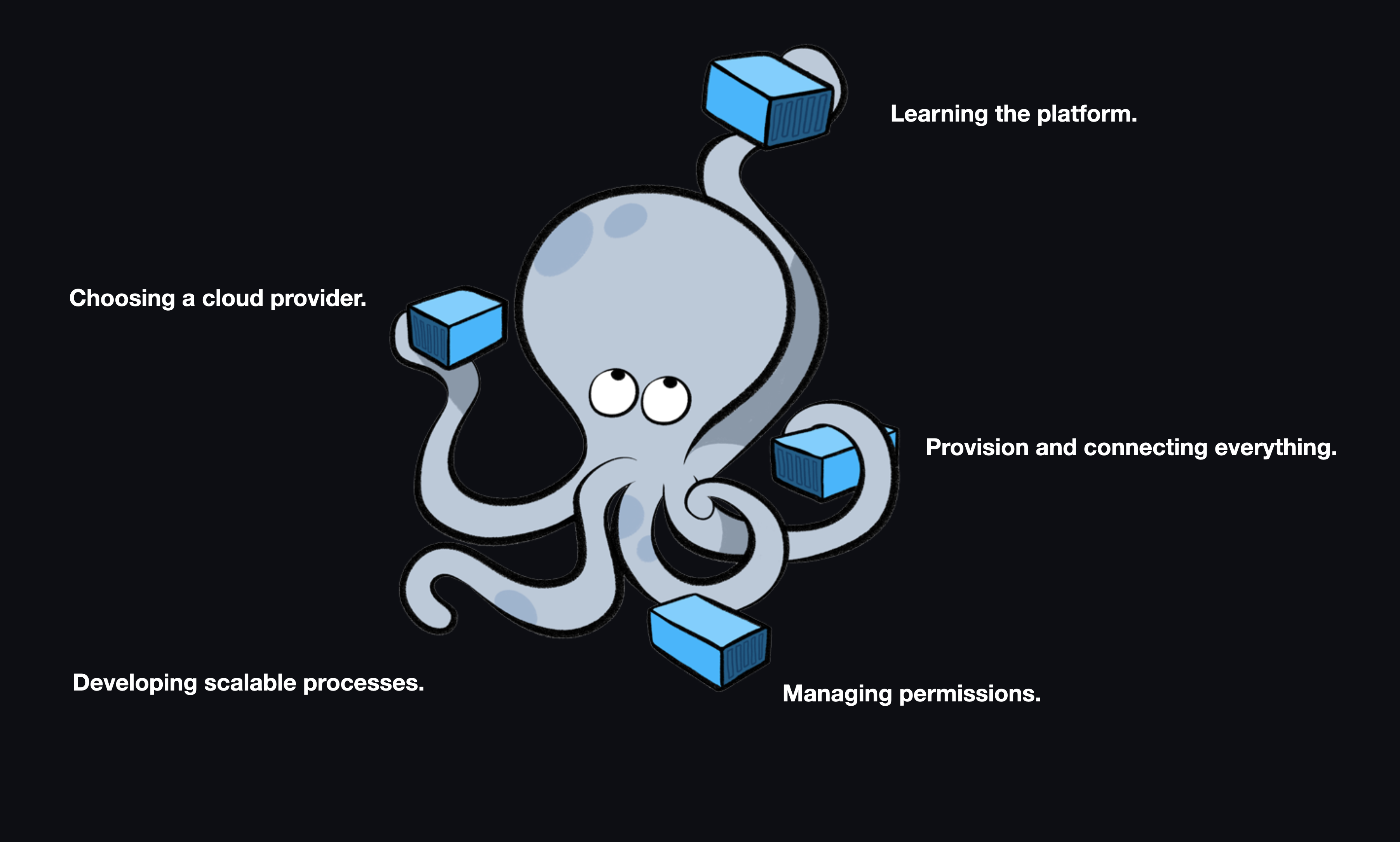
In order for an instructor to take advantage of containerization in the cloud to create and replicate developer environments, they would need to do the following:
- Choose a cloud provider.
- Learn about the different services available through that provider or identify an abstracted solution that works across cloud providers (i.e., Hashicorp's Terraform).
- Provision and connect the various services needed to create containerized environments and make them accessible to students.
- Manage security and permissions to ensure that students (and only students) have access to what they need.
- Develop a scalable process to create and destroy these environments.
Performing each of these steps requires a significant amount of expertise, time, and effort. Fortunately, there are several commercially-available products that achieve these goals without requiring the instructor to be a cloud expert.
4. Existing Solutions
There are a handful of products that abstract away the issues of creating and managing developer environments at scale within the cloud. These are Coder, Gitpod, and GitHub Codespaces.

4.1 Clarifying Criteria
While each of these individual solutions have their own particular strengths, they also come with their own set of tradeoffs. We assessed these solutions against several key criteria:

- Ease of Setup: How difficult is it to get a working copy of this product on your own system?
- Ease of Use: How difficult is it to configure and use the features offered by this product?
- Multi-IDE Support: Does this product let you choose which IDE to use (i.e., VS Code, JetBrains, etc.)?
- Custom Templates: Does this product provide the ability to customize the environment and its dependencies to meet my needs?
- Self-Hostable: Could you deploy this product on an architecture of your own?
- Cost: What are the upfront and recurring costs for a given solution? Do I have to pay a flat price, a price per user, or is there a tiered system involved?
4.2 Tangible Tradeoffs
4.2.1 Coder
Coder is light, fast, flexible, and offers all of the core functionality a developer expects in an IDE. However, getting it up and running on your own system can be challenging. Whether you're using their self-hosted platform or their enterprise product, there's a fair number of obstacles that require manual intervention creating a higher barrier of entry. That being said, Coder provides a reasonably priced platform which charges $35 per user per month.
4.2.2 Gitpod
Gitpod offers an extensive feature set, and aside from a longer startup time, it's also quite fast and flexible. Like Coder, the installation process doesn't always work right out of the box, and it can be challenging to get a working copy of the free-tier product on a local machine. The full range of features offered by Gitpod can make it challenging to configure, making the learning curve rather steep for all of the bells and whistles that it provides.
4.2.3 GitHub Codespaces
Due to its seamless integration with the GitHub platform, GitHub Codespaces offers an easy-to-use, turnkey experience that allows developers to get started quickly. However, GitHub Codespaces limits users to operating only on their platform through the use of an instance of VS Code. Additionally, the environments provided by GitHub Codespaces can be customized to meet individual needs, but the cost of each environment is the most out of any of the available solutions.
Each of these products stand on their own merit, but it became clear that there was one thing they all had in common: all three were designed with a seasoned developer in mind as their end user, and were largely built to accommodate the needs of enterprises.
That's where Armada comes in…
4.3 An Education-First Approach
We built Armada to provide an easy-to-use, low-cost option that was tailor-made for the education space.
Some key features which differentiate Armada from existing solutions include:
- Target Audience: Armada was built with education in mind and aimed to be powerful enough to serve a broad cross-section of instructors and students without being technically burdensome.
- Ease of Use: Administrators can easily create and manage development environments from Armada's UI. After authenticating, all students need is a link to their environment to access it via their browsers.
- Cost: Armada's only cost is the cost incurred from running its underlying resources on the cloud.
- System Ownership: Armada is deployed to an instructor's own AWS account, allowing them to maintain full control over the system and the data it generates.
- Extensibility: Armada is fully open-source. Any sufficiently technical instructor is free to extend the system to suit their particular needs.
Below is a comparison of each product, including their open-source and paid offerings.

5. Armada
5.1 Recap
5.1.1 Challenges
Configuring a development environment presents several challenges, which include:
For Students
- Knowledge of complicated environment configuration and dependency management.
- Access to hardware capable of carrying out common developer tasks and running supporting software.
For Instructors
- Navigating between a compounding number of student hardware configurations, operating systems, software versions, and experience levels.
5.1.2 Goals
In response to these challenges, we developed Armada with the following goals in mind:
- Create easy-to-use development environments for students.
- Make it easy for instructors to manage and deploy development environments.
- Provide the ability to scale to meet student and instructor demand.
- Minimize costs for instructors.
5.2 But First, A Demo
Instructor Workflow: Adding a Student to Creating Workspaces
Student Workflow: Signing In and Accessing Workspace
5.3 The Roadmap
With this information in hand, there were eight key milestones that we needed to achieve in order to create, manage, and serve development environments that instructors and students could make use of, including:
- Containerizing a workspace.
- Provisioning cloud infrastructure.
- Deploying a single workspace.
- Deploying several workspaces.
- Accessing workspaces from dedicated URLs.
- Persisting workspace data.
- Establishing relationships between user data entities and providing a user interface for instructors and students.
- Providing user authentication.
5.4 Containerizing a Workspace: Developing at Scale
5.4.1 Choosing an Environment

Creating the coding environment itself wasn't the primary focus of building Armada. Fortunately, a number of freely available, open source solutions already existed.
As mentioned previously, both Gitpod and Coder offer open-source versions of their paid platforms and products including containerized versions of VS Code, a popular, open-source code editor created by Microsoft. These containers bundle VS Code with its dependencies, exposing it via a network port which can be accessed from a browser. While either solution could have been used as the basis for Armada's workspaces, there were significant tradeoffs for each.
Even in its open-source form, Gitpod offers a number of extensible configuration and customization features in addition to several integrations. However, this comes at the cost of both speed and size. At the time of Armada's initial build, Gitpod's container was roughly 7 gigabytes (GB), and its typical start time ranged from 5-10 minutes. By contrast, Coder's container (code-server) was less than a GB and offered all of the functionality we would need to provide an IDE to students, while being both lightweight and fast with load times under 20 seconds. However, the container is a significantly more limited version of their enterprise product, disabling many key features including groups, custom templates, isolated runners, and high availability.
Given that one of our main goals was to keep costs down, we chose to use the Coder image as our base since it would allow us to provision more instances of the workspace container per server than the GitPod image.
We now had containers that would run on our local machines and were able to provide individualized workspaces that could be accessed in the browser. Our next challenge would be running a single container on a server in the cloud.
5.5 Gaining Access to the Cloud
5.5.1 Starting from Scratch
In order to begin building Armada, we needed to make a key architectural decision: would we focus on a single cloud provider (cloud native) or ensure that Armada works across all platforms (cloud agnostic)? Making this decision would have real-world implications for the reliability, scalability, and maintenance cost of our application.
Cloud Native
"Cloud Native" is a development philosophy that centers around building applications with technologies that are "native" to a specific cloud service provider. One of the most useful features of a cloud-native approach is that it allows developers to avoid undifferentiated heavy lifting, meaning that the operational burden of managing IT services is delegated to the cloud provider. This allows developers to focus on building the application's core features. However, by limiting the application to one cloud service provider, the developers become locked into that provider's framework, sacrificing the freedom to move their application to a different cloud provider's platform without substantial rewrites.

Cloud Agnostic
A cloud-agnostic approach revolves around designing applications that can be deployed to any cloud environment using open-source technologies. Building cloud applications in this way gives developers the ability to avoid vendor lock-in.

The additional flexibility offered by writing applications to work on any cloud provider is not without tradeoffs. It is easy to garner the impression that cloud agnosticism means that a single code base will work on all cloud platforms, but that is not the actual case. In reality, a fair amount of work has to be done to adapt the application to run on each cloud provider's environment.
Additionally, using open-source technologies intended to support cloud agnosticism can add significantly more complexity. Developer responsibilities could expand to include activities such as applying security patches, updating virtual machines' operating systems, and managing backups. Unfortunately, these duties take valuable time away from other tasks, such as creating new features or resolving user issues. While the cloud-agnostic approach is meant to improve flexibility and portability, it often introduces significant logistical and maintenance overhead.
Amazon Web Services (AWS)
After considering the advantages and disadvantages of each architectural approach, we decided to take a cloud-native approach and host our application on Amazon. AWS provided several services that would enable us to focus on development instead of system administration.
In addition, AWS has a vast tooling ecosystem that integrates seamlessly with the platform,providing a cohesive developer experience. AWS exposes a multitude of different tools including the Command Line Interface (CLI), Software Development Kit (SDK), and Cloud Development Kit (CDK), which greatly improved our ability to prototype and iterate.
5.5.2 Spike then Automate
As we set out to construct Armada, our primary focus was on creating a consistent, reproducible environment that could be easily shared amongst our team and inform a deployment strategy for our future users.

Amazon enables the programmatic provisioning of resources through its Infrastructure-as-Code (IaC) product, CloudFormation. CloudFormation enables developers to request and customize any AWS resource using files written in either YAML or JSON. However, these files are often tedious to maintain and require an extensive, granular focus on specifying roles, permissions, and dependencies.
To make it easier to specify the correct configuration, Amazon provides an abstraction on top of CloudFormation known as the Cloud Development Kit (CDK), which allows developers to create CloudFormation templates and customize resources using one of several prominent programming languages.
Through our use of the CDK, we were able to create, share, and incrementally extend our architecture with ease. This was important, as Armada's cloud native nature required that it be built from the ground up with the benefits of the cloud in mind. We needed to understand how specific pieces of the architecture would interact and communicate and the only way to do that was through the platform rather than developing Armada locally and viewing the cloud as a deployment target.
5.5 Deploying a Single Workspace
5.5.1 Workspaces in Motion
With our workspace container squared away, we needed a viable method for constructing, serving, and managing our containerized developer environments in the cloud.
5.5.2 Walk, Then Run
In order to understand how our containers would interact with their hosts, we needed to be able to focus on the simplest iteration of our product: A single unmanaged container deployed in a cloud environment. For this task, we made use of AWS's Elastic Cloud Compute (EC2) service, which provides and manages virtual servers, which we could then use as hosts for workspaces. Since workspaces in Armada are defined as Docker images, we began by installing the Docker Engine on an EC2 instance and configured that container to open a network port so that it would be accessible from an outside connection.
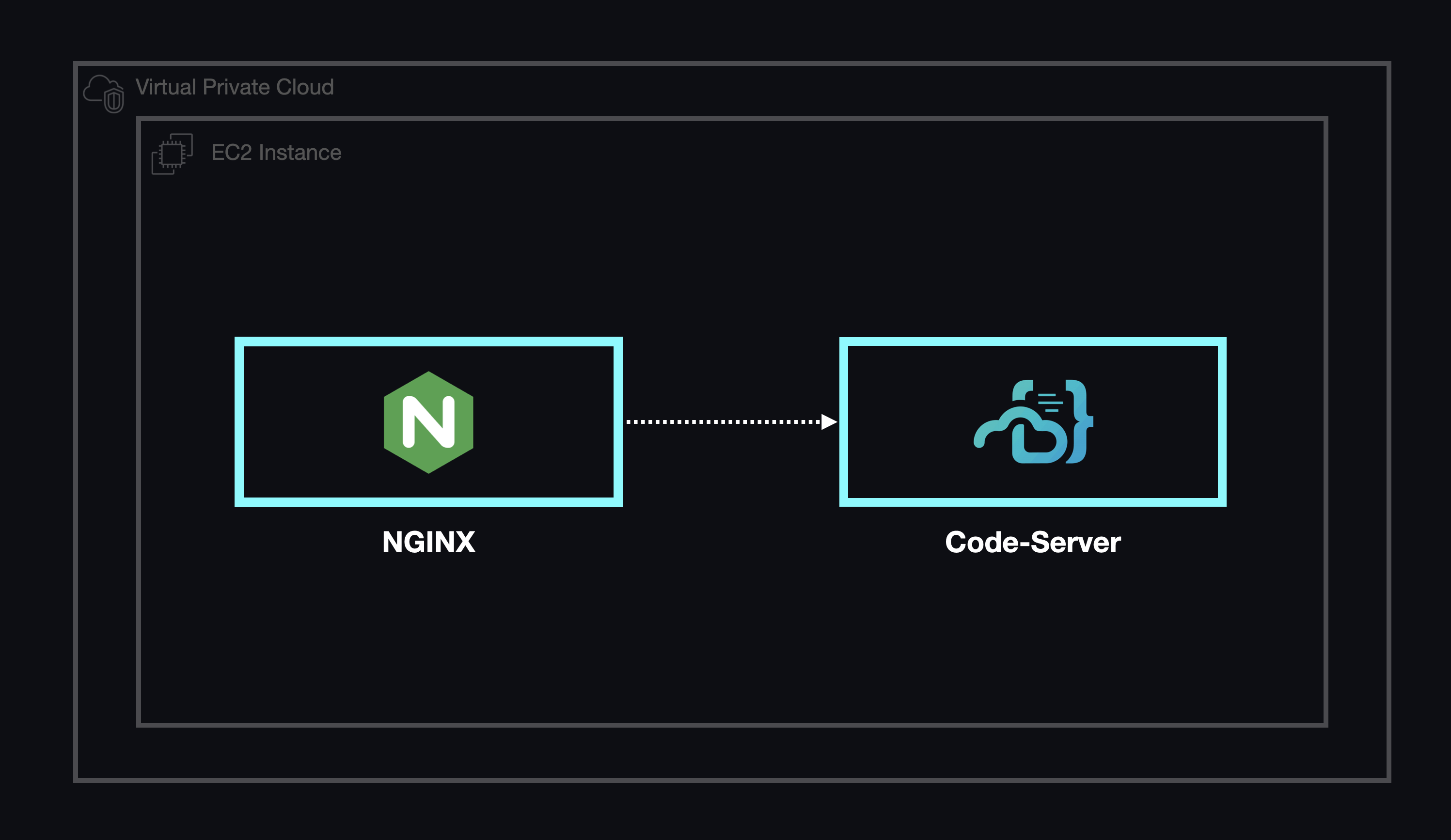
Overall, this process didn't offer much in the way of automation and would not have been practicable at scale. While our initial focus was on a single environment, it was important to consider the need for the ability to deploy multiple environments simultaneously in the future.
5.5.3 A Symphony of Software
Automating the deployment, management, scaling, and lifecycle of containerized applications deployed across multiple machines, also known as container orchestration, is a common issue in the world of software development. The Docker Engine on its own is not sufficient to meet these challenges at scale. As such we looked to several different open-source and cloud native solutions, including Kubernetes, Docker Swarm, and Amazon's Elastic Container Service (ECS).

Kubernetes
Kubernetes is a mature, actively-maintained, open-source technology. The richness of its feature set was highly attractive, but those features also came with a proportionate level of complexity. We concluded that since we would only need a small subset of the functionality provided by Kubernetes, it would be better to use a less powerful technology that addressed our needs.
Docker Swarm
Docker Swarm is a part of the Docker Engine and therefore has far fewer dependencies than Kubernetes. Additionally, the time required to learn how to deploy a cluster of workers managed by Docker Swarm is much less than what would have likely been needed to use Kubernetes. However, it is not without its drawbacks. Using Docker Swarm would have required the Armada team to construct and implement complex mechanisms for managing container logging, handling container health checks, and scaling the underlying architecture based on demand (i.e., controlling the number of provisioned EC2 instances).
Elastic Container Service (ECS)
The Elastic Container Service (ECS) provided by Amazon struck the right balance between a rich feature set and ease of use. ECS allowed us to provision a managed cluster of containers via Amazon's Cloud Development Kit (CDK). Furthermore, we were able to configure ECS to spin up containers or tear them down as needed without burdening the Armada codebase with the logic required to perform orchestration. Additionally, ECS integrates with other AWS services and grants us the ability to autoscale both containers and the hardware required to host those containers. It also provides a mechanism for monitoring and logging containers, creating the ability to recover crashed student workspaces without requiring the instructor to intervene.
5.4 Key Terminology
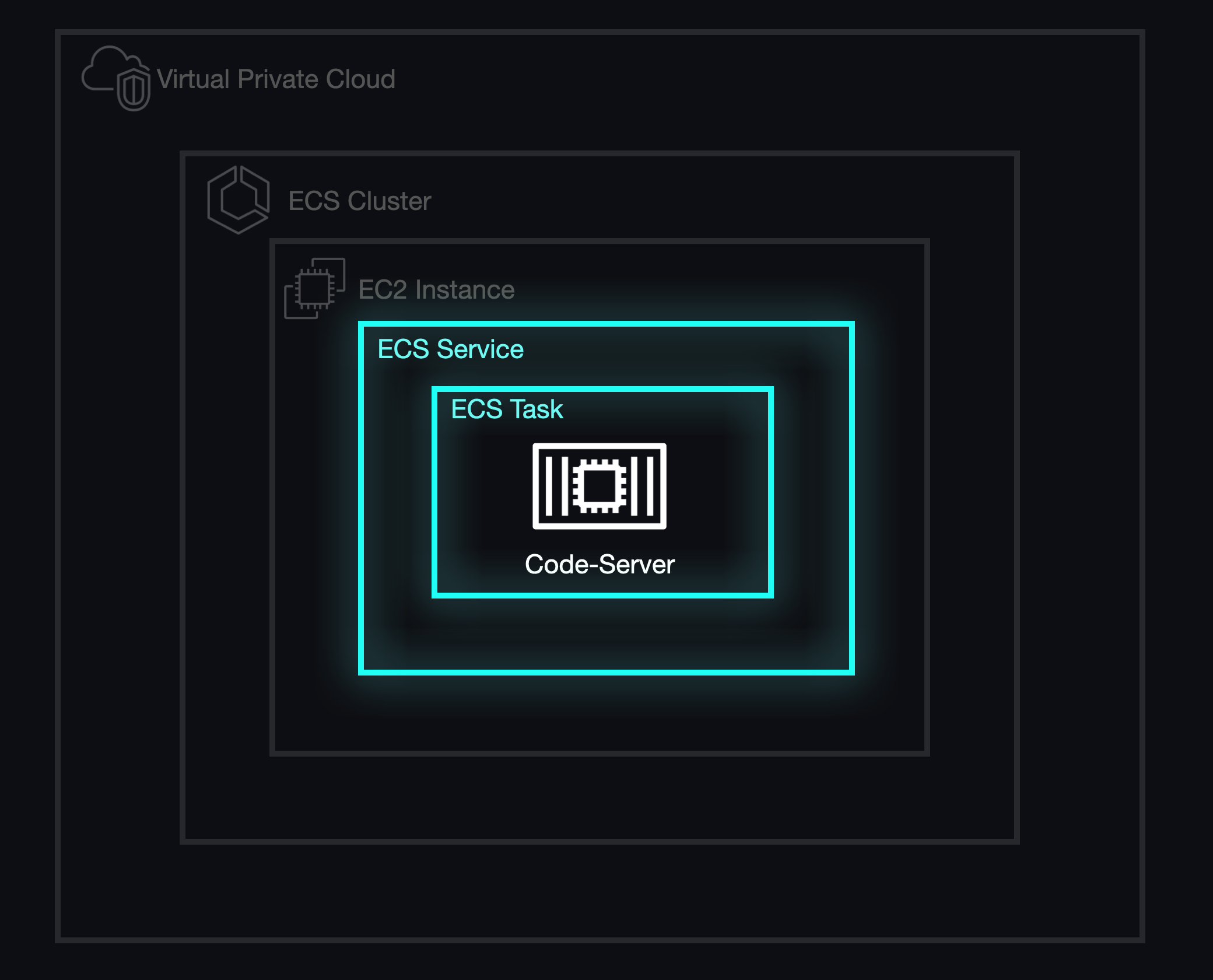
In order to fully grasp the way Armada's workspaces eventually functioned within ECS, it's necessary to review some key terminology.
ECS provides the ability to create containers via task definitions, which are analogous to how a Docker image is derived from a Dockerfile. Container images are published to an image registry such as Docker Hub or Amazon's own registry called the Elastic Container Registry (ECR). In addition to specifying what images to use, task definitions can configure different parameters for a container such as port mapping, data volumes, and memory usage.
After a container or set of containers has been defined as a task definition, ECS allows you to run these containers as a task. A group of tasks running together is called a service. Services allow for finer-grained control over the group of tasks, including the desired count and percentage of tasks to maintain in a running status along with networking configuration. Finally, a cluster is a group of tasks or services that together encompass an entire application.
5.5 A Task at a Time

In its initial form, Armada utilized individual tasks and task definitions to pull a custom image from Docker Hub that included code-server, Coder's open-source VS Code image described above. This allowed us to run and deploy our developer environments as proof-of-concept and enabled individual workspaces to be accessed via the Internet.

5.6 Moving Forward
With this approach, we gained the ability to provide isolated developer environments in the cloud. However, running workspaces as individual tasks did not give us fine-grained control over the health and monitoring of their containers. Therefore, we began searching for a way to manage multiple workspaces in a way that would scale without introducing fragility.
5.6 Deploying Multiple Workspaces
In order for Armada to operate as a fully-fledged product, we needed to be able to serve an arbitrary number of users simultaneously. Therefore, we needed a method for not only managing the lifecycle and health of our developer environments but for scaling the infrastructure running those containers.
5.6.1 The Problem with Tasks
By operating exclusively with tasks, we weren't able to respond to any unexpected errors within our containers, which meant that our tasks could stop without any recourse. Additionally, tasks did not offer an option to configure networking, which would become extremely important when we set out to match the correct task to the correct student workspace. Eventually, we concluded that we would need ECS services to meet our goals.
5.6.2 A "Healthy" Alternative
Services enable ECS to automate the monitoring and management of containers. ECS performs health checks by making requests to a predefined URL which replies to ECS with a 200 response if the service is perfectly operational. If a container is deemed "unhealthy", ECS will automatically destroy and replace the containers defined by the tasks in the service.
In the case of Armada, we only needed to run one task per service for each student's workspace. As an added benefit, this configuration provided us with a method to start and stop individual workspaces by updating the number of running tasks for a given service from zero to one task and vice-versa.
With services in place, we needed to address an underlying issue with how the infrastructure for our ECS cluster was being allocated. Although ECS manages individual services and tasks, the actual containers run on individual EC2 instances which have a finite amount of available resources, most importantly memory (i.e., RAM). Luckily, AWS provides a method for creating a pool of resources that can scale horizontally with demand known as an autoscaling group (ASG).
5.6.3 To Infinity and Beyond
We defined an autoscaling group for the EC2 instances that would act as hosts for our workspace containers. We configured this autoscaling group to add capacity based on the amount of memory reserved for each individual service. If the memory reserved for all tasks hosted on an individual EC2 instance exceeded this reserved bound of its total memory, the autoscaling group would instantiate a new EC2 instance to accommodate the additional demand. This same mechanism enabled us to automatically eliminate an EC2 instance if the resources are idle.
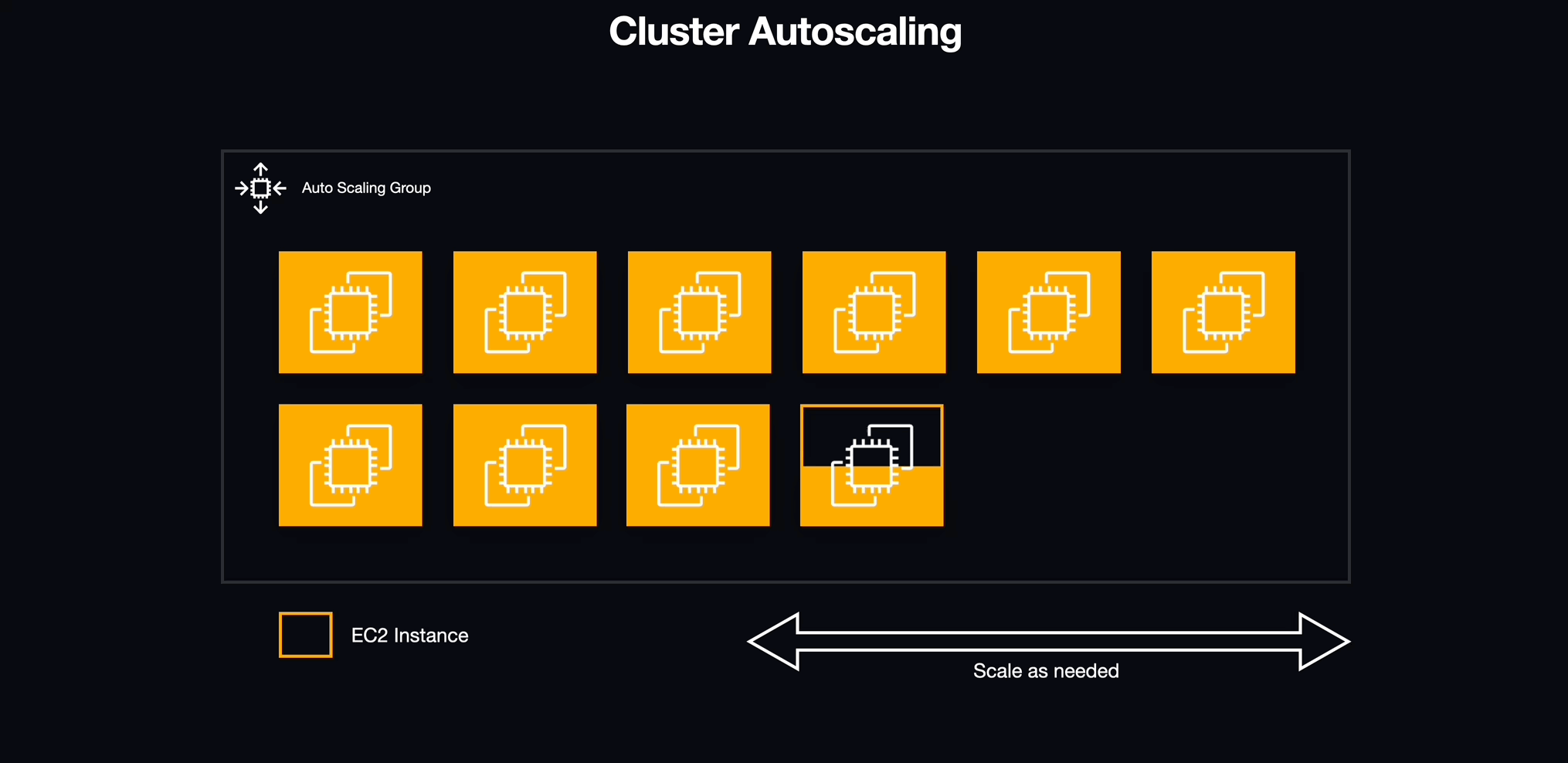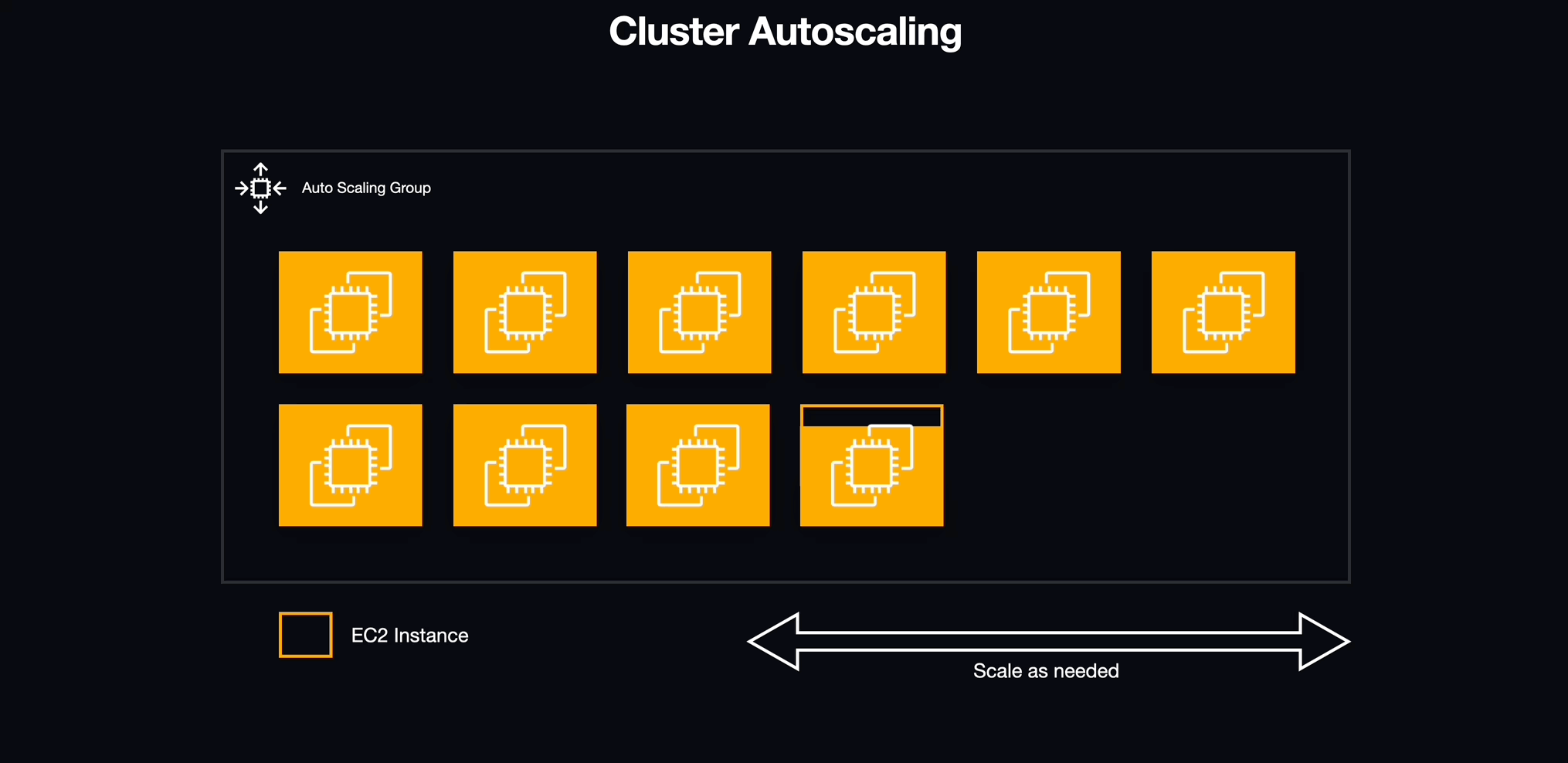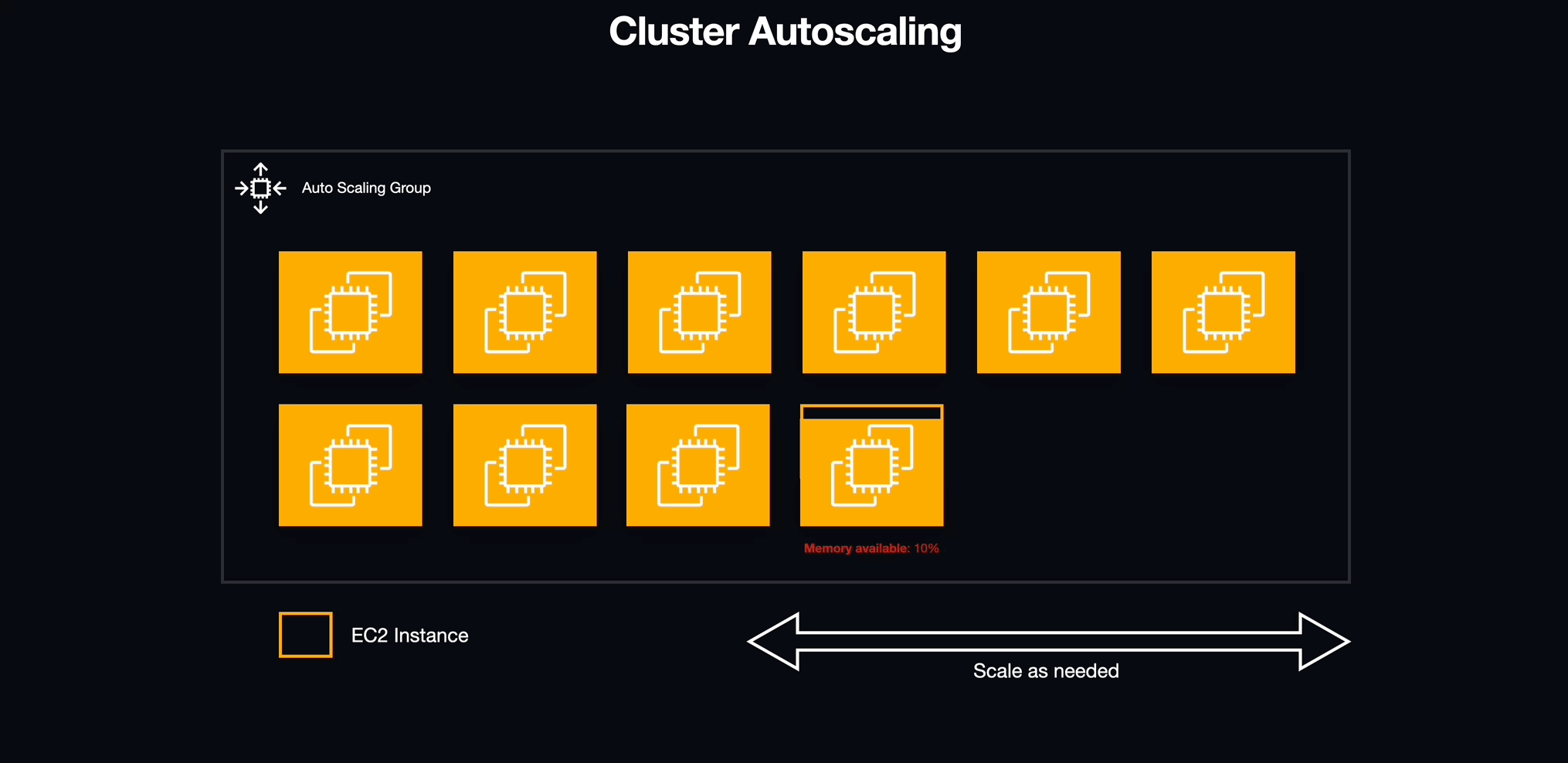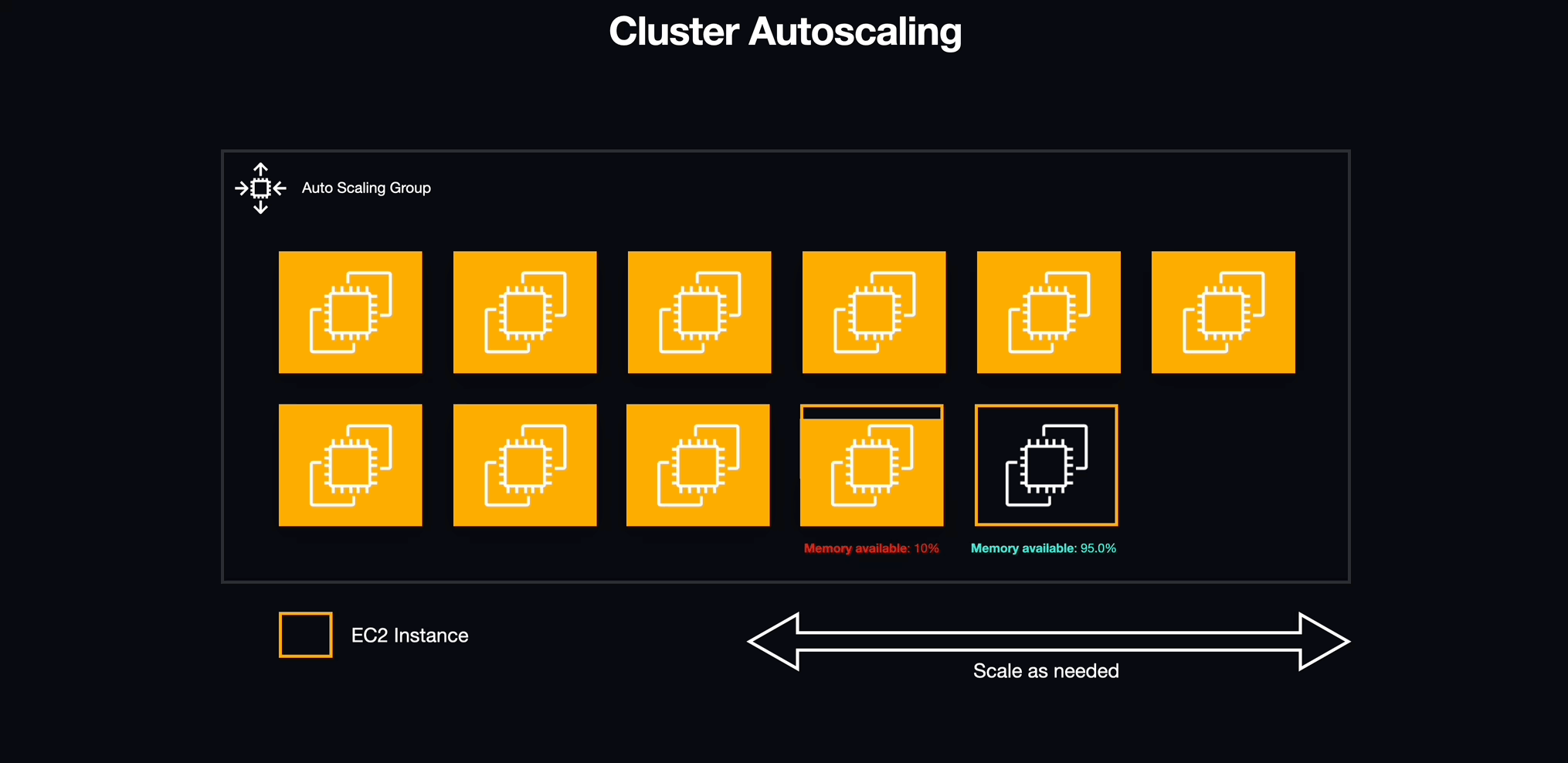
5.6.4 Look Who's Scaling Now
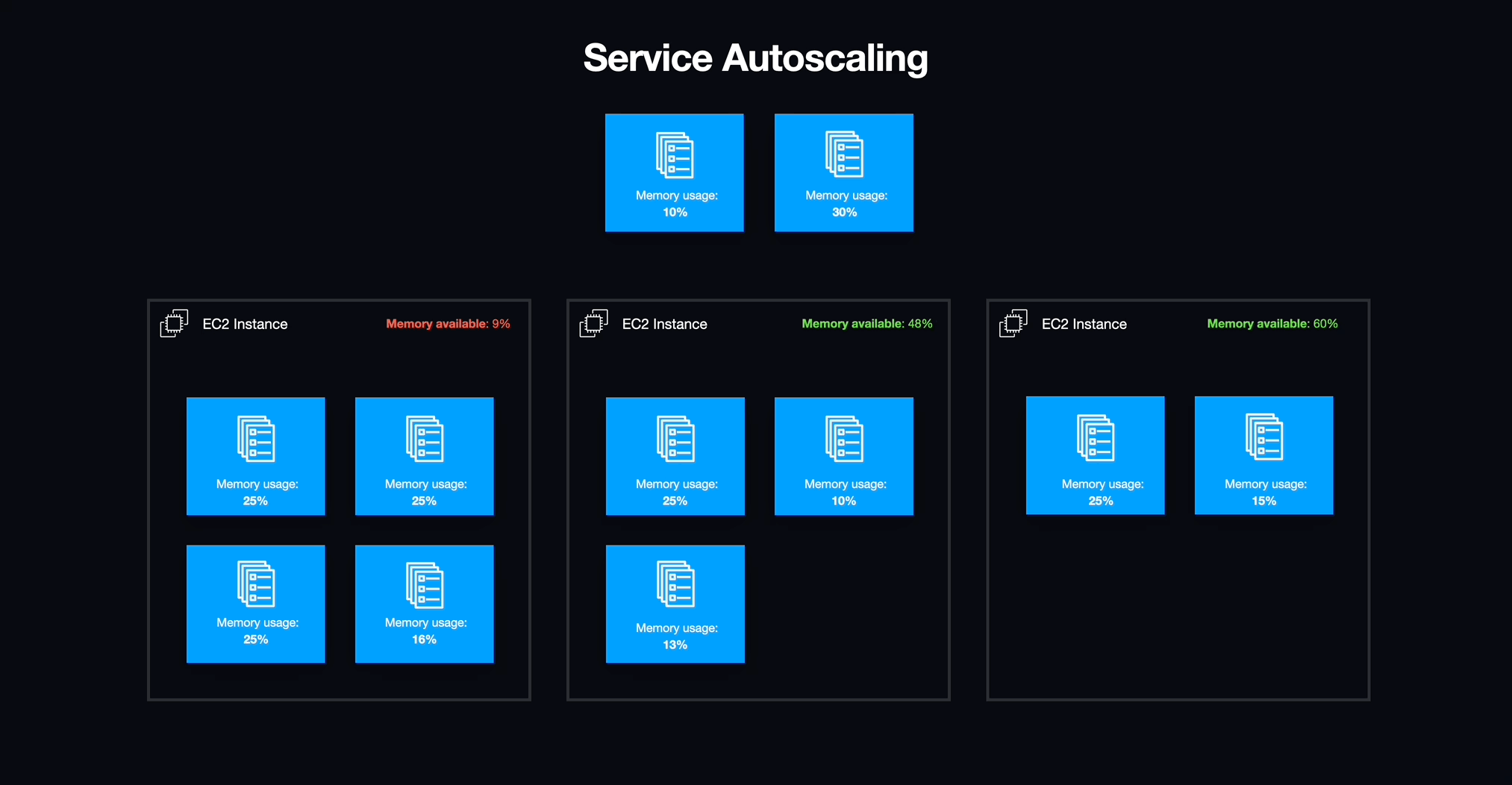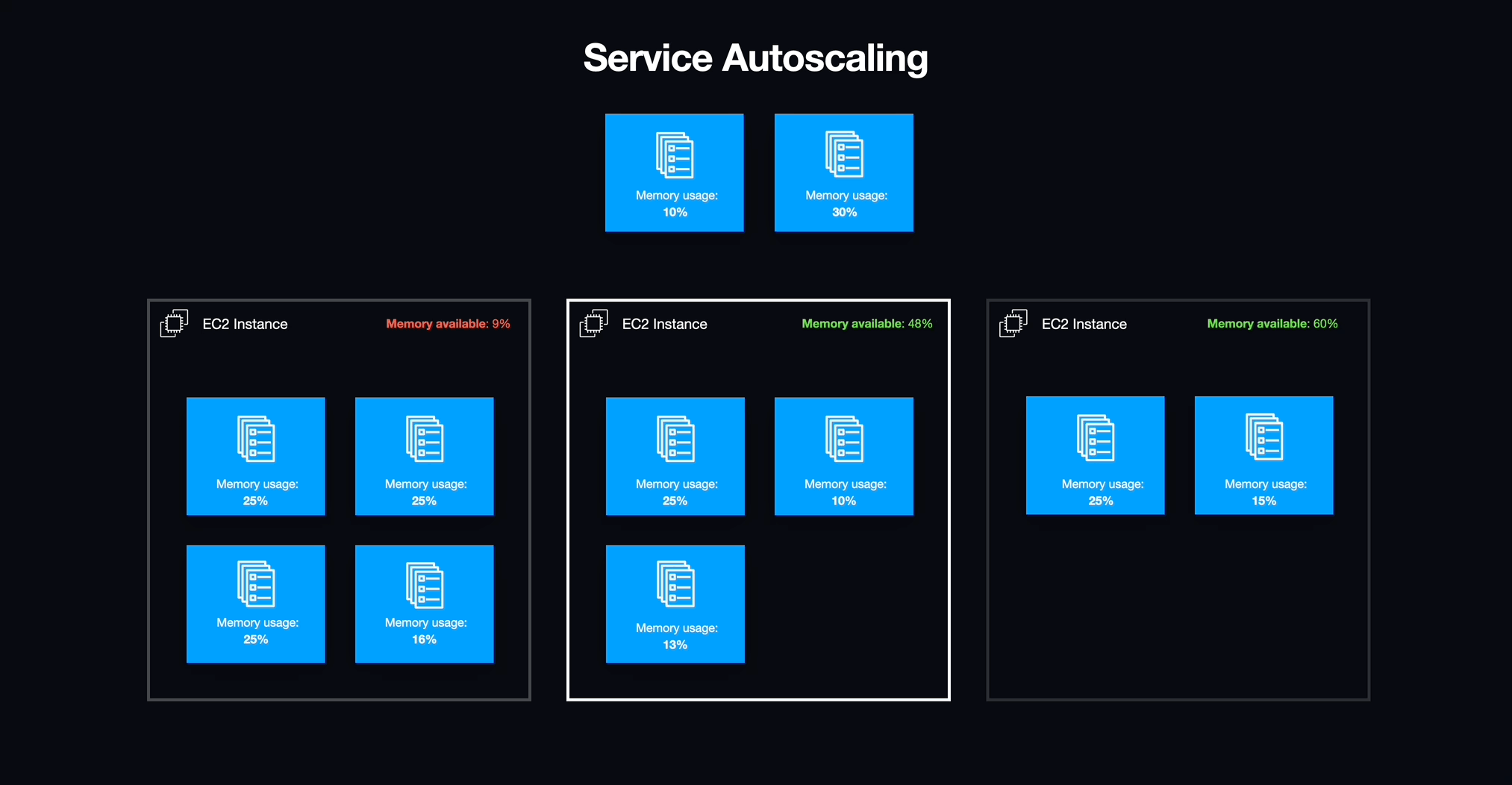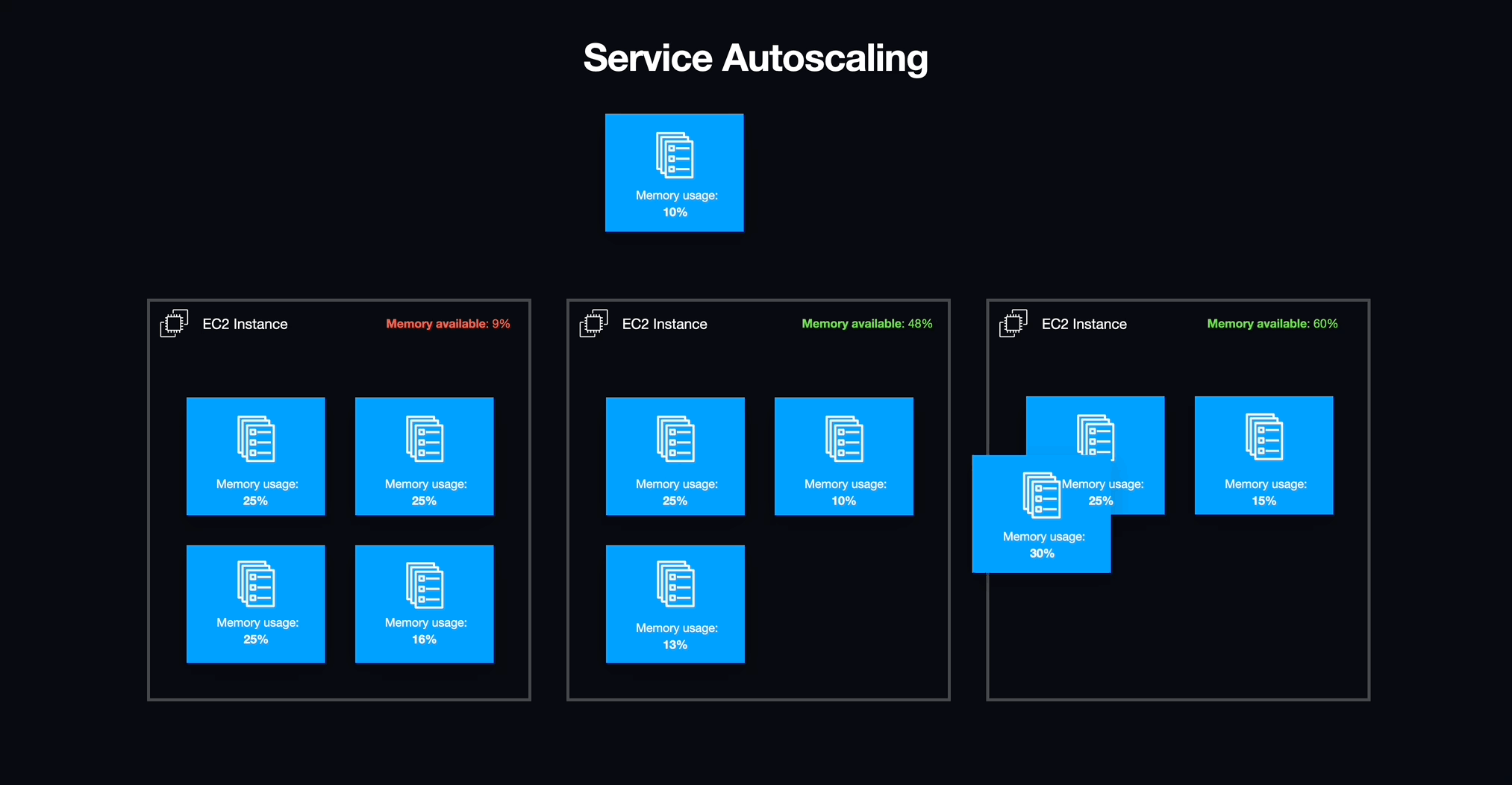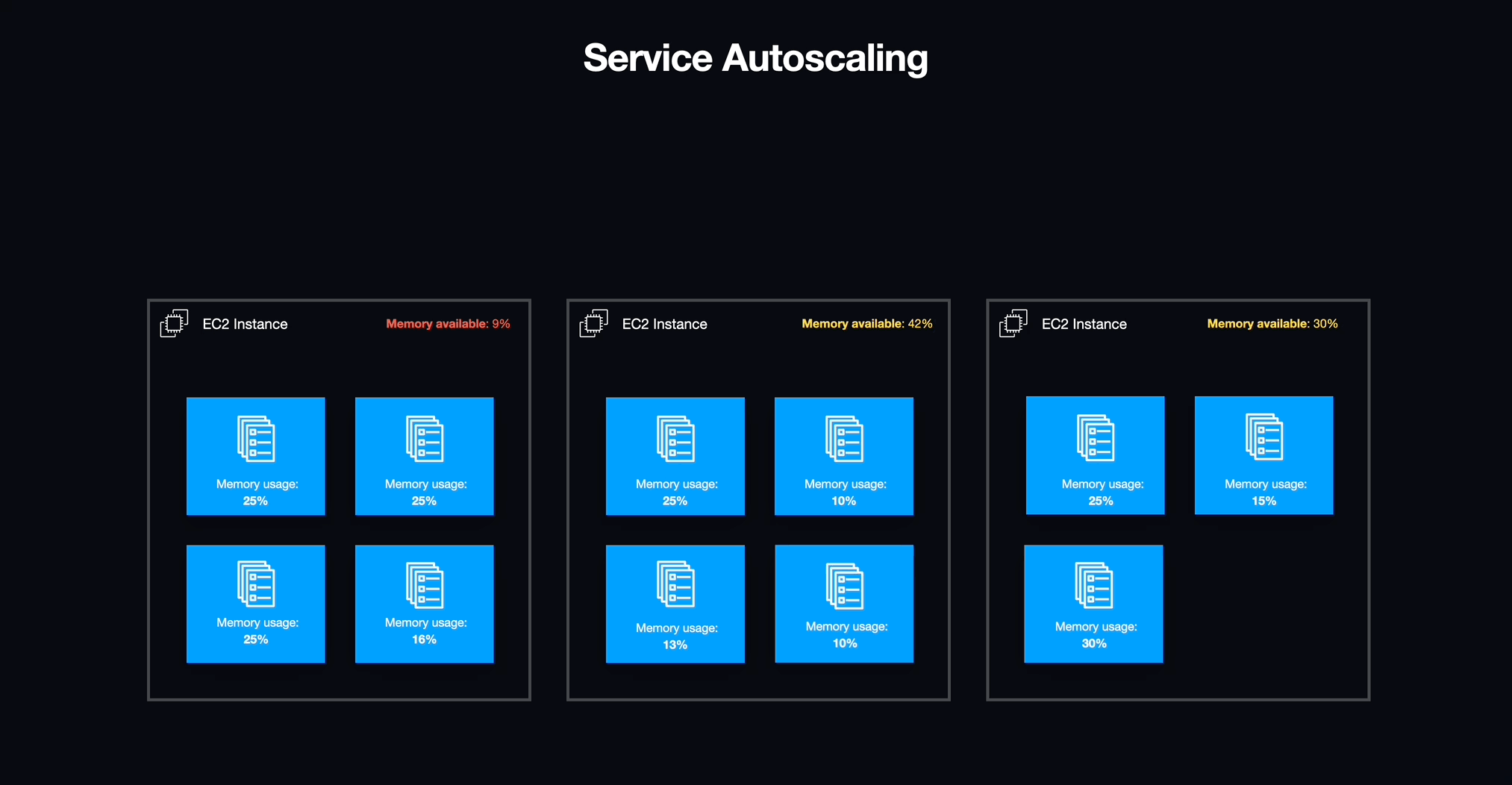
With workspaces now defined as tasks under management by ECS services, we were able to easily turn workspaces on and off as well as manage unexpected failures within the workspaces themselves. We also gained the ability to scale EC2 instances to precisely meet the needs of running workspaces without wasting overhead. Services also offered one additional benefit that allowed us to solve a problem with providing workspaces to students that we would not have been able to easily address otherwise: Networking.
5.7 Routing
5.7.1 From Port to Port
Up until this point, we'd been deploying individual workspaces on separate EC2 instances, because we'd hardcoded the container ports used in our task definitions. This was not the most efficient way to use EC2 instances, since each EC2 instance has enough resources to host multiple workspaces simultaneously. However, enabling multiple services to reside on the same host added significant complexity, because each successive workspace would need to guarantee that the ports it exposed on the host were not in use by another process or workspace. It turns out that this is quite a common hurdle when deploying containers on ECS.
5.7.2 Added Complexity: A Deep Dive
Containers essentially operate as isolated virtual machines that share the underlying resources of their hosts rather than deploying a guest operating system per container. As such, containers maintain their own set of port mappings and settings. When we define a container, we're able to determine which ports on our host operating system (i.e., our actual computer) map to those within the container itself. We can either define a set port for the container to use (static port mapping) or allow the host operating system to dynamically choose a port based on which ports are available (dynamic port mapping).
Static Port Mapping
If we relied on static port mapping, we could not deploy a container using the same host ports that were being used by another container. For example, if we have a task definition with a host port of 5000 and a container port of 8080, we can't launch another ECS task that uses the same host port of 5000.
In order to temporarily bypass this roadblock, we continued tearing down and deploying our infrastructure, deploying one workspace to each EC2 instance in our ECS cluster. This gave us some leeway to keep experimenting while we searched for a more viable solution.
Elastic Load Balancing (ELB) and Dynamic Port Mapping
We eventually landed on a potential solution to our networking challenges with Elastic Load Balancing (ELB) by using it as a load balancer in front of our ECS cluster, serving as the entry point into our application.
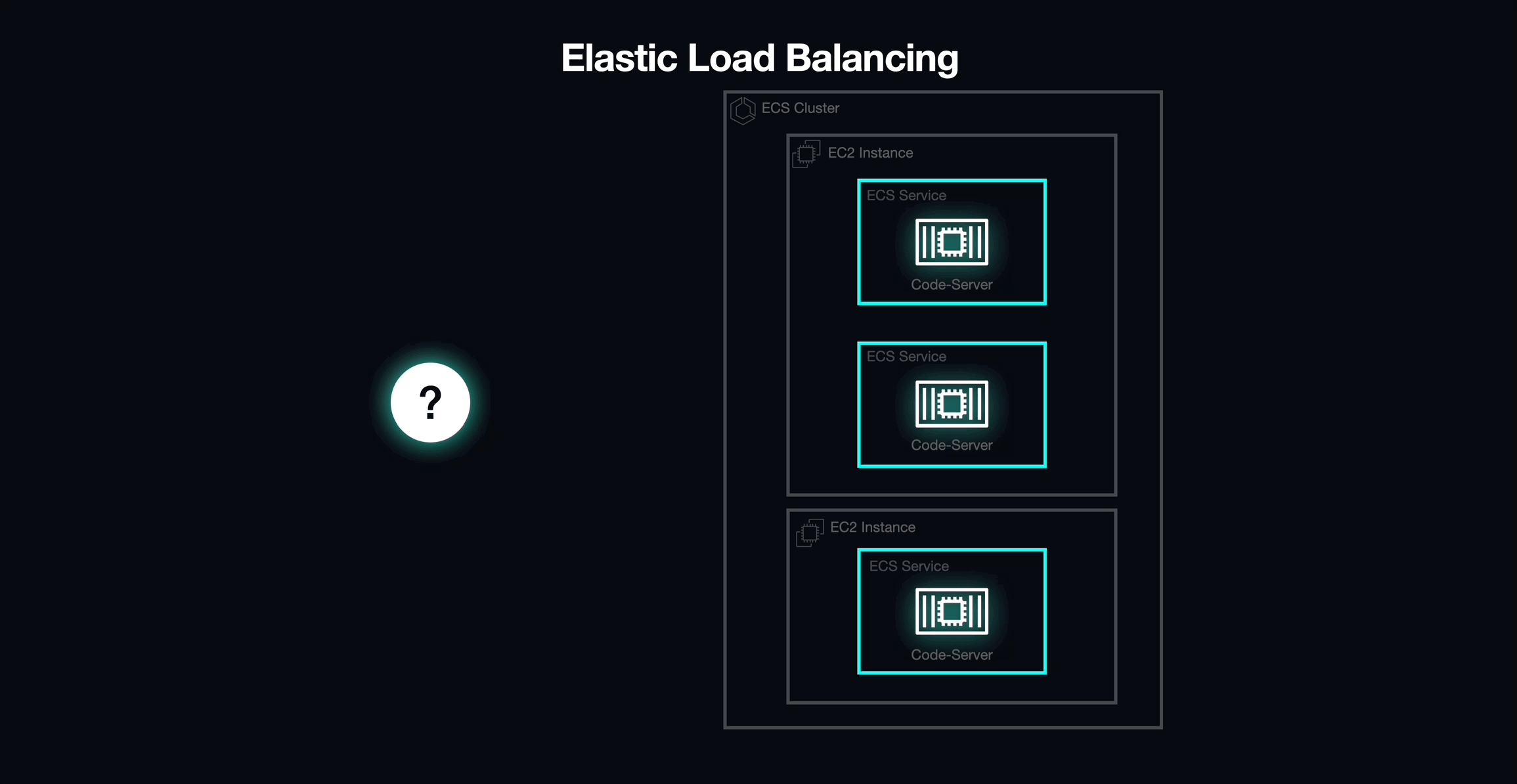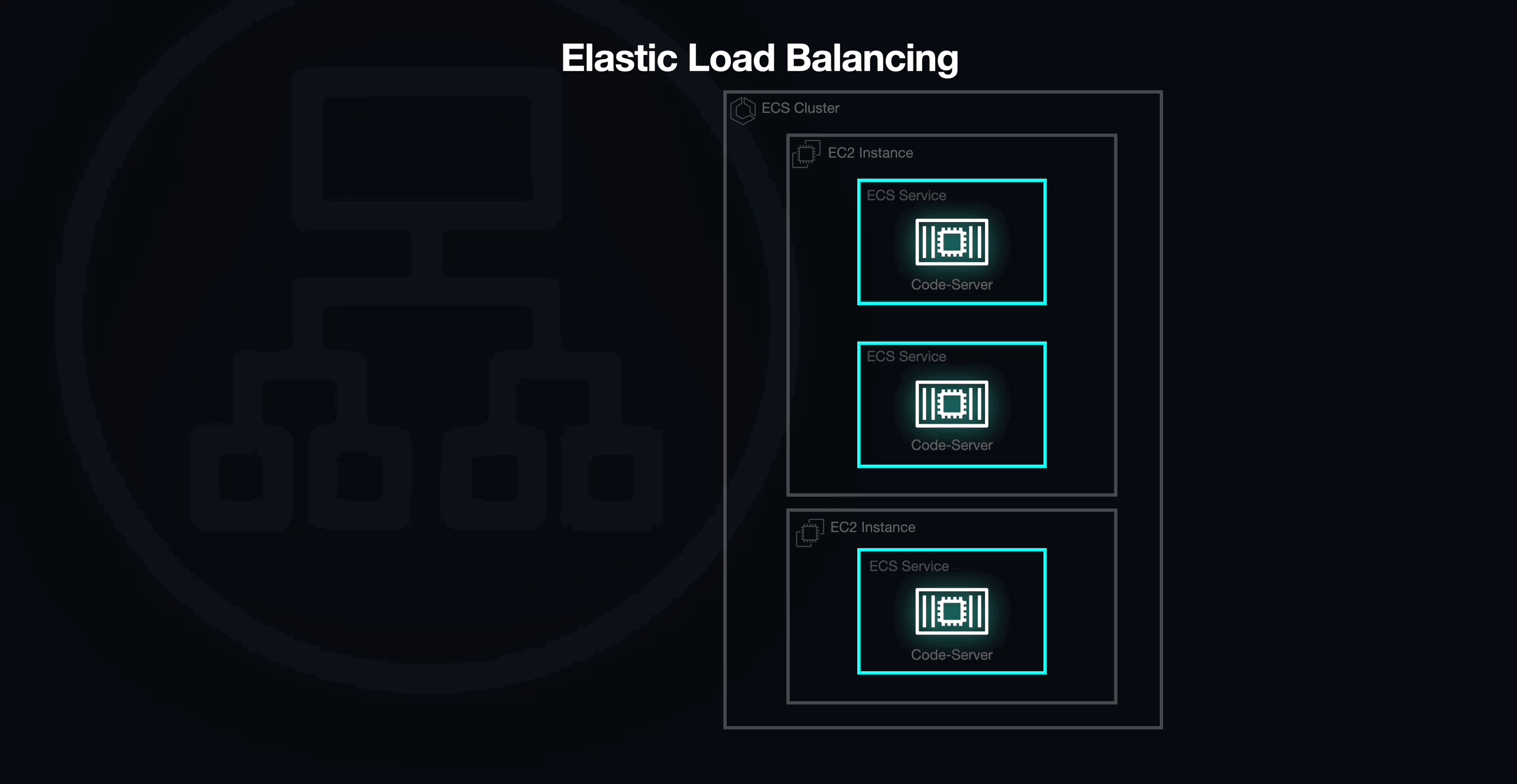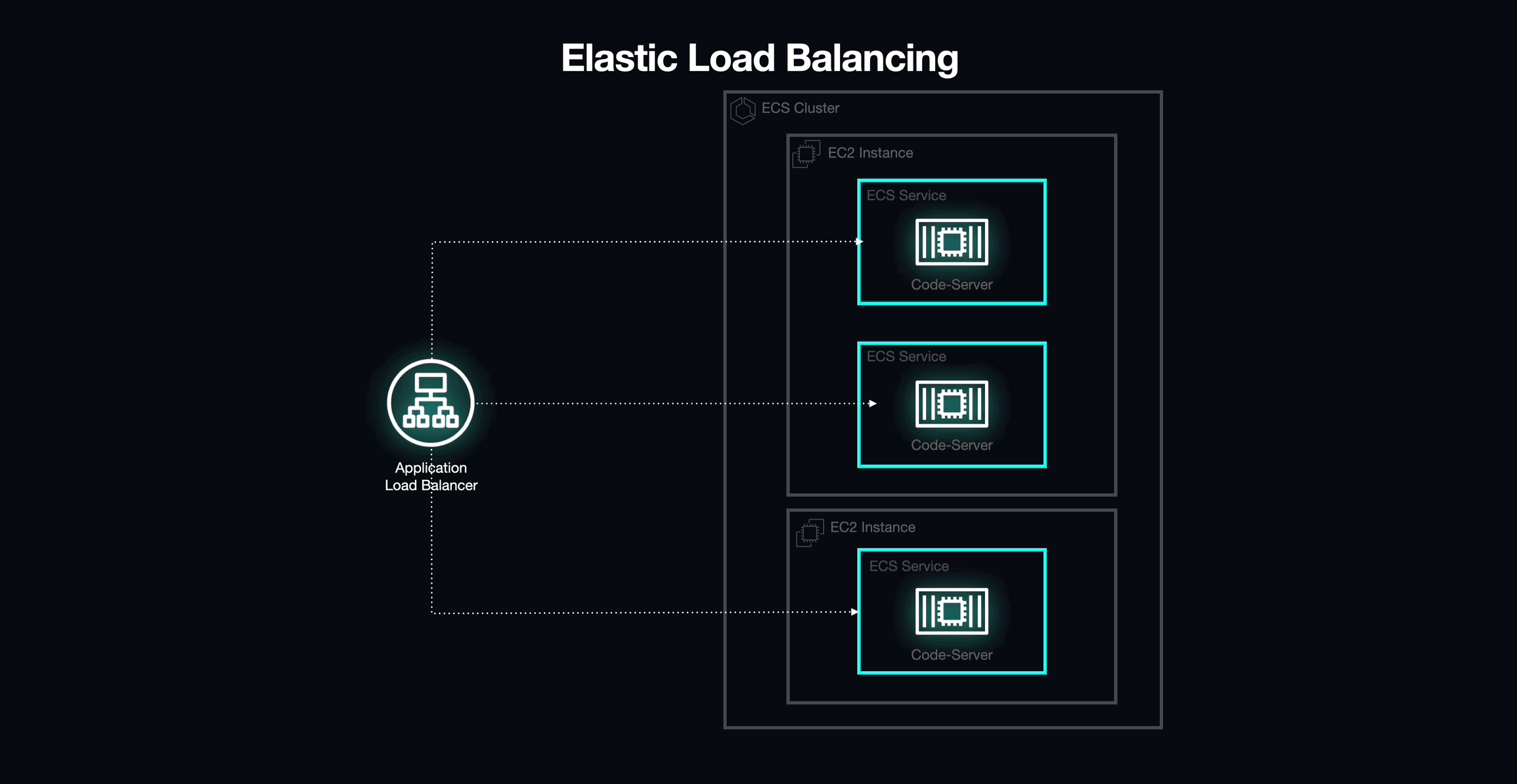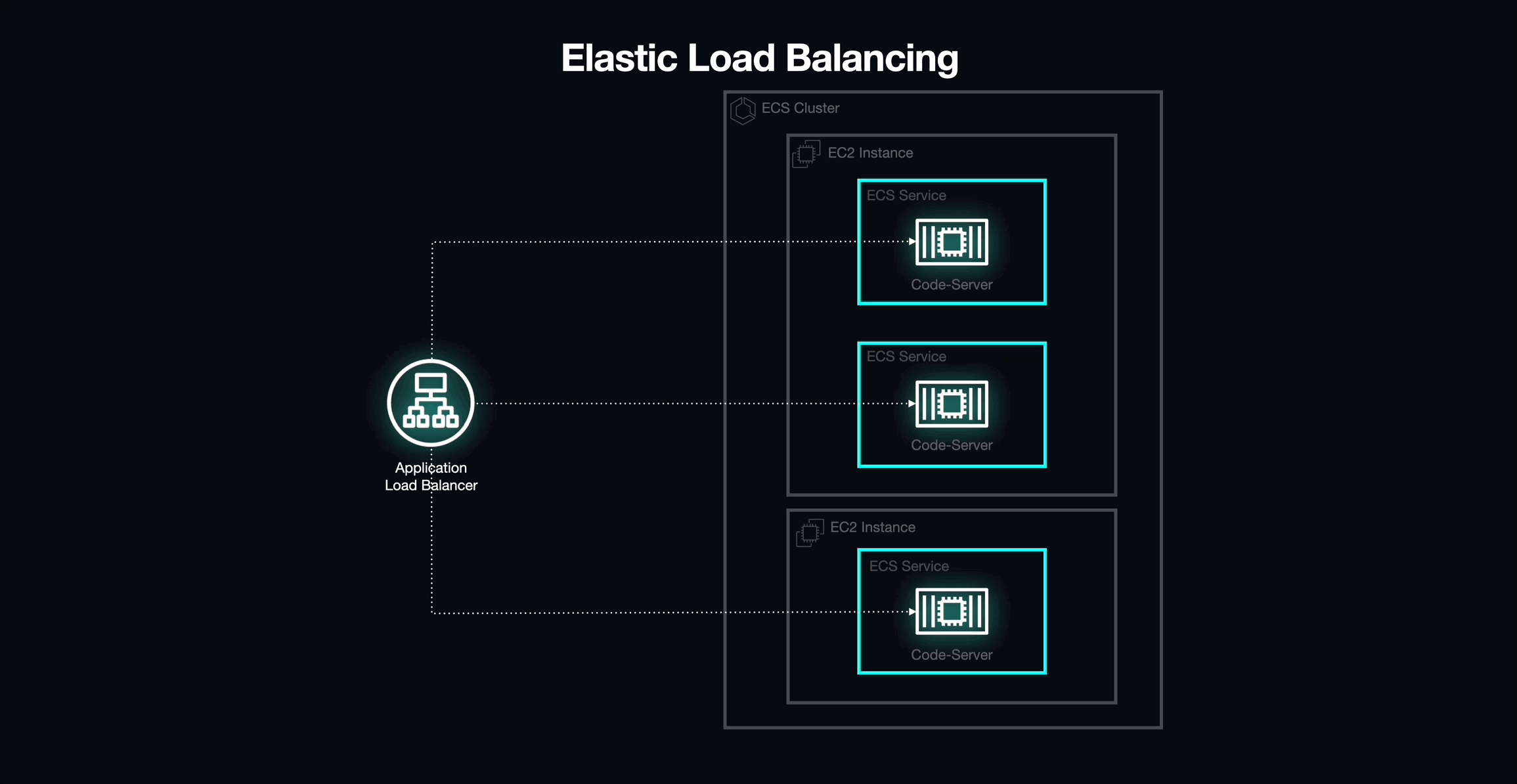
Out of the four different load balancing options offered by ELB, we selected the Application Load Balancer (ALB). The ALB integrates seamlessly with ECS and provides a few key features that helped us overcome several of the challenges imposed by static port mapping.
The ALB supports dynamic host port mapping, which would allow us to deploy multiple tasks on the same EC2 instance. In order to take advantage of this behavior, all we needed to do was update our task definitions to indicate that selecting a host port would be the ALB's responsibility. When the ALB encounters a task configured in this way, it automatically selects an available port from the ephemeral range on an EC2 Instance. However, this led to another challenge.
Unintended Consequences
Typically, a load balancer is used to distribute traffic across a fleet of horizontally-scaled servers. However, Armada's workspaces are stateful: each one "belongs" to a specific student. By default, ALBs use a round-robin routing algorithm, which ensures that traffic is routed to each of the load balancer's targets in an evenly distributed manner (i.e., one after the other). This meant that every time the ALB endpoint was hit, the incoming request would be forwarded to a completely different task, which would result in a student connecting to a random environment instead of the one dedicated to them, not the intended behavior.
Segmenting Traffic: Target Groups
In order to overcome this issue, we chose to map each individual workspace to its own target group. A target group is a collection of one or more logical resources that can receive traffic from a load balancer, which, in turn, provides the ability to segment traffic to specific resources based on URL.
Application Load Balancers (ALBs) can attach listeners to each available port on which they expect to receive traffic (i.e., Port 80). Each of these listeners contain one or more rules that define where a specific request should be routed. Typically, these pathways are routed to specific target groups based on the path contained within the URL used to reach the ALB.
In the case of Armada, we use our consistent naming structure (i.e., cohort-course-student) to define the resource path for each workspace's unique URL, and each rule is then created and attached to the ALB listener when a new task is defined.
By taking advantage of this path-based routing structure alongside dynamic port mapping, we were able to maintain a one-to-one relationship between workspaces and routes. As a result, each workspace could be given a unique path that would enable it to be accessed from a single base URL. Each workspace was then linked with its own NGINX container, allowing us to rewrite the portion of the URL used for path-based routing and enabling each workspace to be addressed as though it were a standalone application.
5.7.3 Looking Inward
With each of these pieces in place, we were able to successfully automate the distribution of our developer environments. We could efficiently host multiple environments on a single EC2 instance, scale to more EC2 instances if needed, and provide a consistent method for accessing the correct environment.
Now that our overarching infrastructure was largely solidified, it was time to turn our efforts inward and focus on providing a complete user experience.
First up, we needed to provide a reliable way for our instructors and students to persist their data irrespective of the lifecycle of their developer environments.
5.8 Data Persistence
One of the major issues we faced as we were developing Armada was determining how to persist data. Containers are inherently stateless, so each development environment that exists in a container does not save user data when the container stops running or otherwise shuts down. In other words, any changes a student makes to a workspace would be lost if not for persistent storage, so we needed to find a way to save data beyond the life of the ECS container.
5.8.1 Storage Wars

When using Docker containers locally, volumes are used to persist data. However, volumes can not be used in a straightforward manner within a cloud environment due to their distributed nature. Therefore, we needed a more sustainable approach to storing volumes on a remote host and matching data to the correct container upon startup. In order to accomplish this, we explored two major avenues - using the Elastic File System (EFS) or Elastic Block Storage (EBS) in conjunction with S3 buckets.
Elastic Block Storage (EBS)
EBS is a service that creates a virtual hard drive that can be mounted to an EC2 instance and treated as a block device. Using EBS originally seemed like a great way to get read/write storage for the workspace off of the workspace's physical host. However, these volumes are typically tied to the lifecycle of their hosts, introducing more volatility than necessary. Turning off or destroying an EBS volume would mean losing all of the student's data. For us to be able to store user data written to the EBS volume, we would need to create an S3 bucket to save a snapshot of the data.
The process that we worked out for using EBS to persist user data was:
- A student creates a new workspace.
- We retrieve the latest snapshot of data stored in the S3 bucket that is unique to the user.
- We query the Elastic Container Service using Amazon's UUID for the new workspace to get the UUID of the EC2 host of that workspace.
- We attach the EBS volume to the EC2 host for the workspace.
- On workspace shutdown, we create a new snapshot of the EBS volume and overwrite the stale data in the S3 bucket. Then we detach and destroy the EBS volume along with the workspace.

Limitations
Once we were able to establish that it was technically possible to use EBS and S3 in this manner, we also found that there were a number of issues that made it a suboptimal solution. Using EBS/S3 largely precluded us from being able to scale workspaces easily and efficiently. EBS mounts directly to a virtual server in much the same way that a USB drive can be plugged into your desktop, which meant that we would have to work out a way to programmatically determine what mount points were available on the workspace host, and how to tell the newly instantiated workspace where that volume could be found. Solving both of these problems would mean writing custom scripts for the EC2 host that could discover and provide that information to both AWS and the workspace on the fly, an approach that we regarded as fragile and difficult to manage. If we decided to use this solution to provide persistent storage, we likely would have been relegated to running a single workspace per EC2 instance.

One of our primary goals when building Armada was to have a system that would scale student workspaces efficiently, meaning that we would use the minimum amount of computational power required to provide a smooth user experience. We ultimately decided to abandon EBS/S3 as a way to save user data between sessions, and instead turned our attention to Amazon's Elastic File System (EFS).
Elastic File System (EFS)
EFS is a serverless, cloud native storage service that provides an on-demand, scalable file system. Where EBS creates a virtual hard drive that can be mounted to a server, EFS acts instead as an extension of an operating system's file system. It allows for data to be stored without the need to maintain storage capacity because the file system will grow and shrink according to the needs of the application. EFS works by monitoring a specific directory and uses serverless functions to mirror changes made to files in that directory. As a result, data is persisted regardless of the state of the container or its host.
With EFS, we could much more readily predict and control how a workspace would connect to its storage. We immediately saw this as a tool that could fit our project's needs, since being able to attach our storage directly to a workspace without having to care about the workspace's host was a significant advantage. However, we had some reservations about EFS's pricing model and cost when compared to EBS. In the end, EFS proved to be the best fit for our use case of saving data for each student workspace that fit seamlessly with ECS.
Missed Connections
Despite its benefits, implementing EFS still had its complexities. Using the CDK, we were able to provision an instance of EFS with the required security groups and networking configuration. Our first effort to implement EFS as a workspace's storage mechanism involved creating a task definition for each student workspace where a specified EFS volume could either be created or retrieved on startup.
However, in order to successfully attach and utilize EFS within Armada, there were two key components that needed to be present. First, the specific folder or directory being used on EFS must exist within the EFS volume itself before it can be mounted to a given container. Next, each task definition for a container must specify a mount point for the EFS volume that will be attached when the container is created, enabling the location of the directory to be configured based on the container's needs.
To resolve this issue, we used AWS Lambda functions to create uniquely named directories that would contain the EFS volumes mounted for each individual workspace. AWS Lambda runs serverless functions in response to predefined events. In our case, the Lambda function for creating the EFS mount point is triggered whenever an instructor creates a new task definition for a specific workspace.
The directories created as mount points for EFS followed the naming convention of "cohortName-courseName-studentName/coder" and within the container definitions for each workspace, that directory was mapped to "/home/coder".
To summarize, the order of events for using Lambda in conjunction with EFS to run our workspaces was as follows:
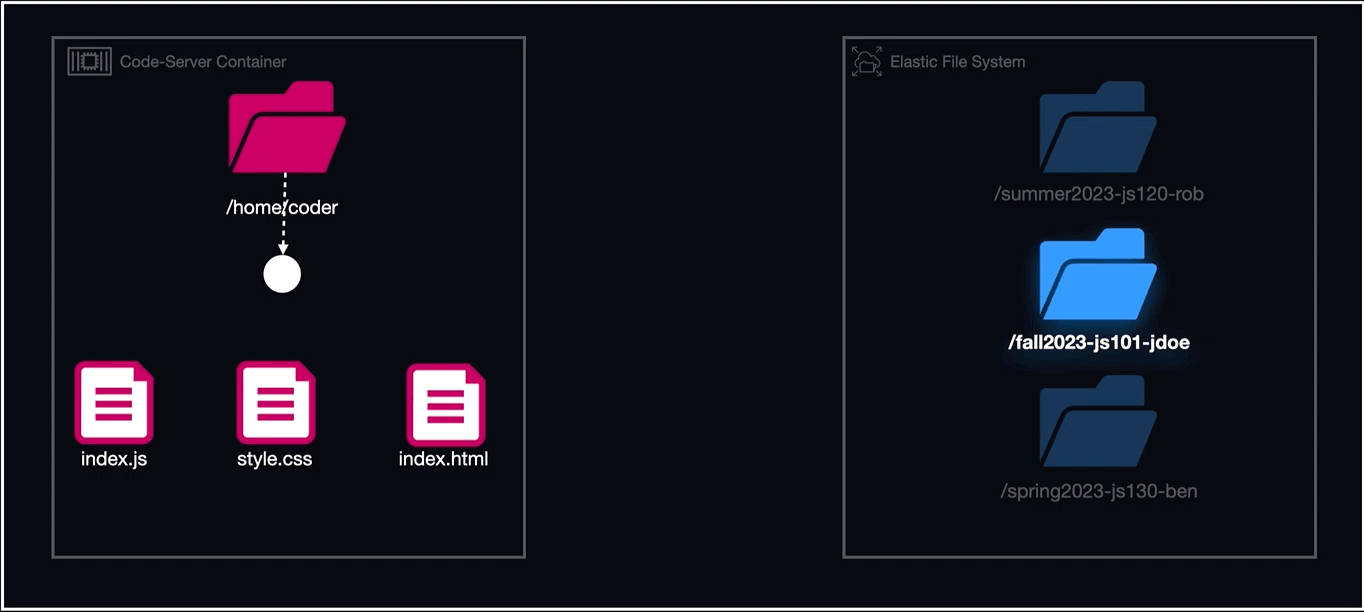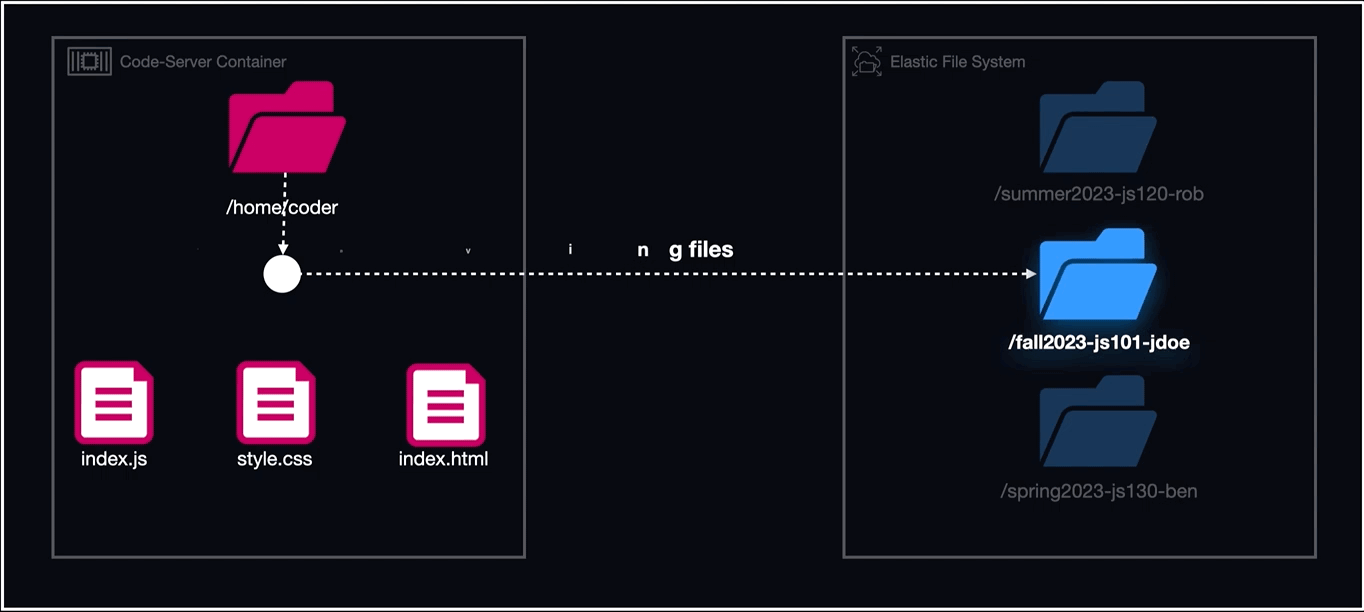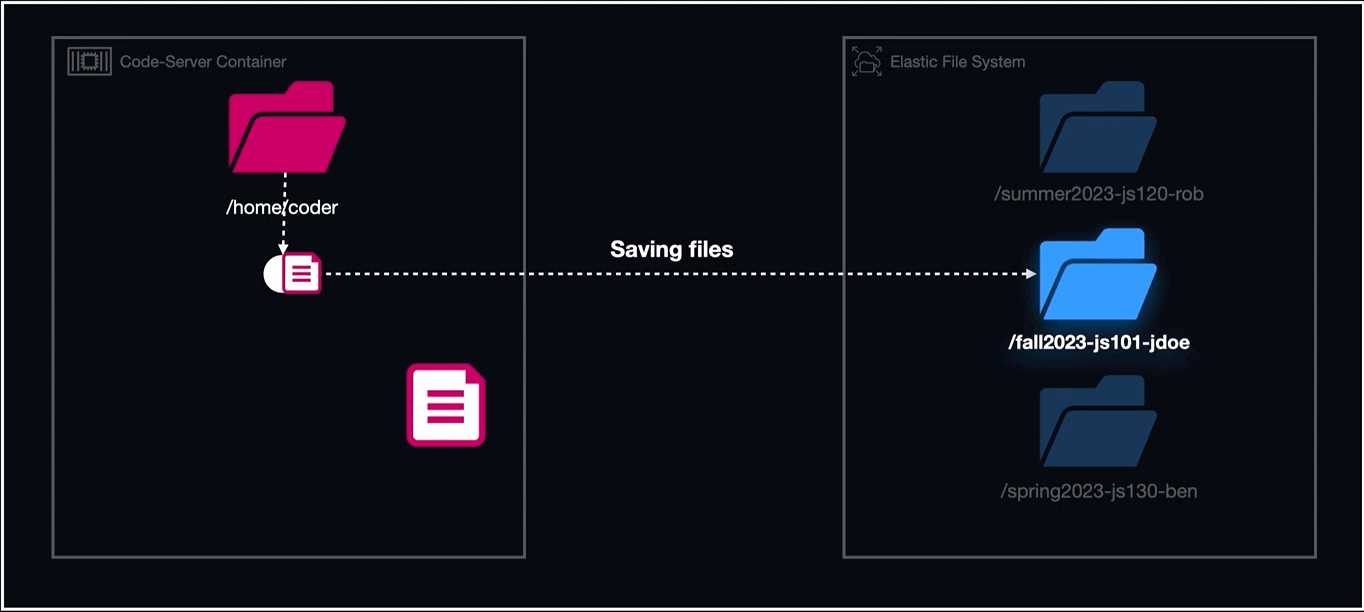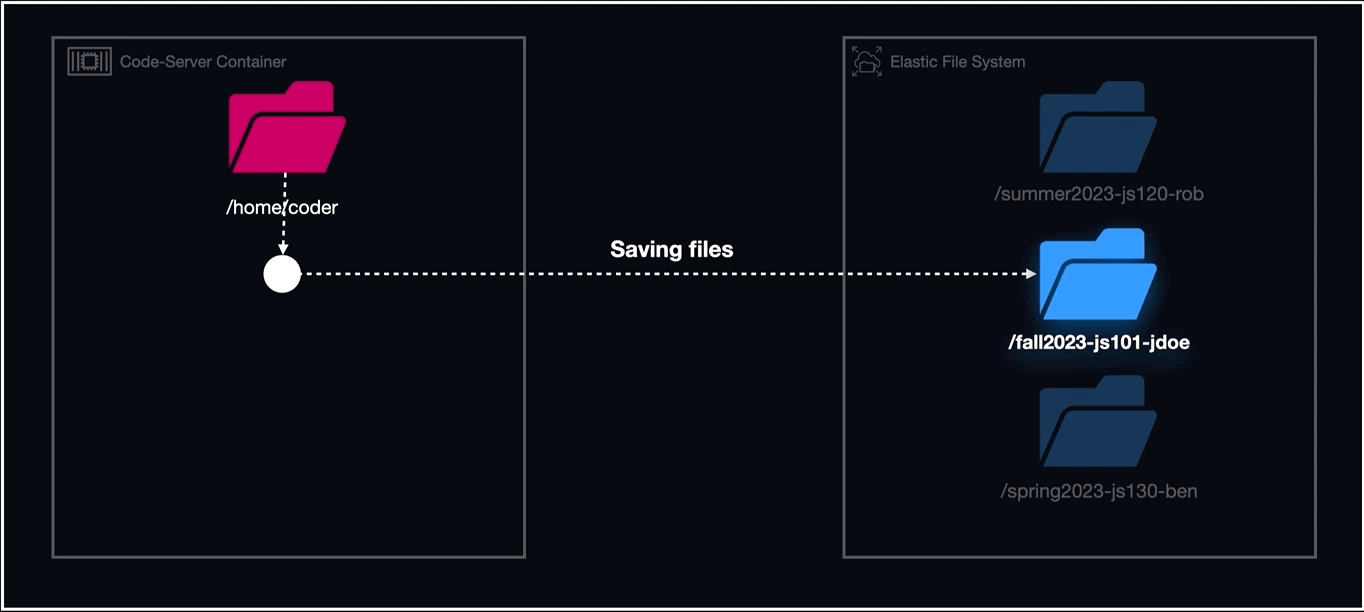
- Create a task definition referencing a volume that is a uniquely named directory on EFS.
- Using Lambda, create the directory within EFS that the task definition references in its EFS volume configuration with the naming convention of cohortName-courseName-studentName.
- Run the task (workspace) with the EFS volume mounted to a container directory called "home/coder".
5.8.2 Great Success
With a data persistence solution in hand, we were able to successfully save students' work from one session to the next. Now, students could be sure that their data would be there, regardless of any interruptions or failures.
Looking forward, we needed a way to expose all of these established resources to our instructors and students in a straightforward and intuitive way.
5.9 Improving Communication
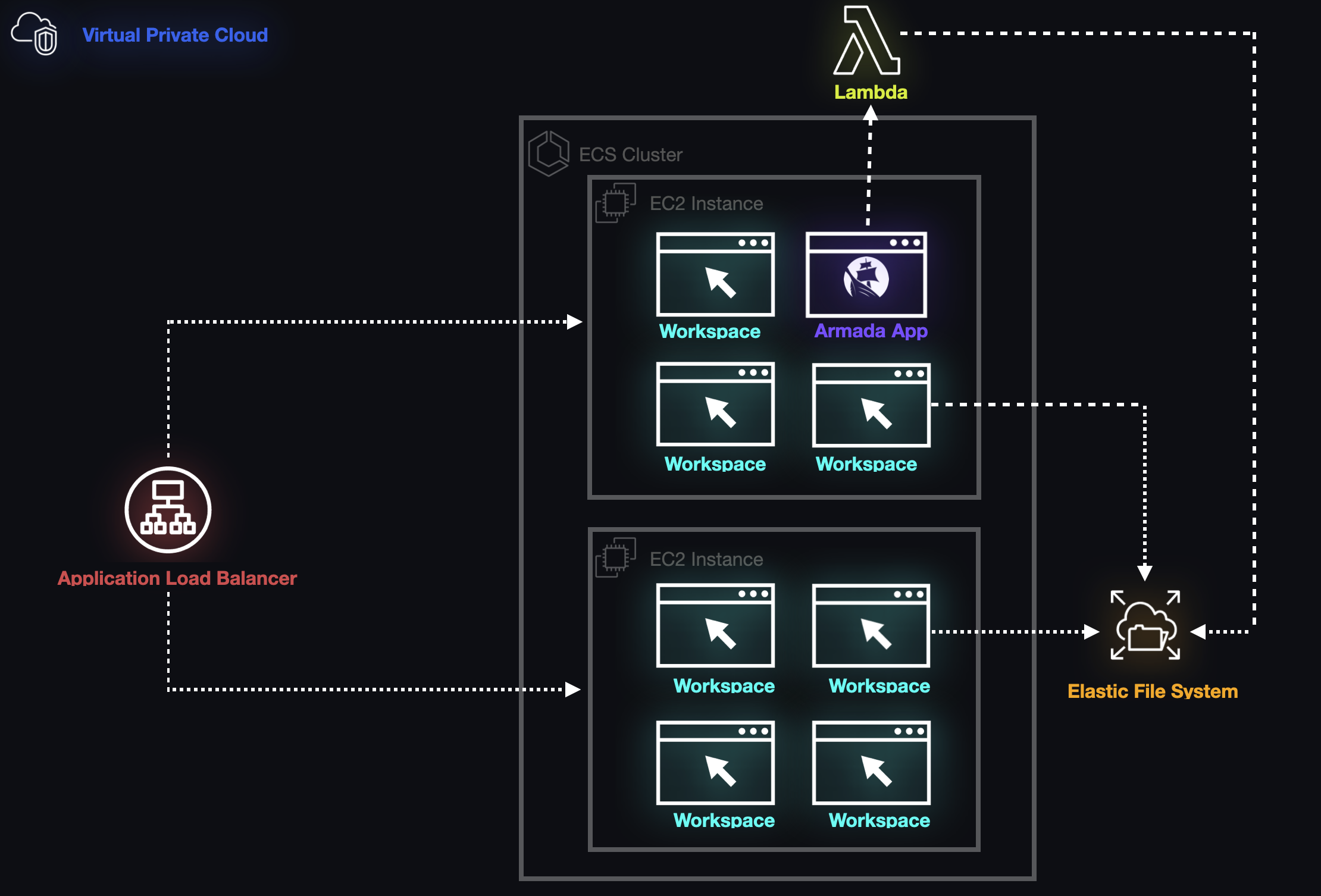
To provide communication between the different pieces of our architecture, the Armada team needed to give instructors the ability to programmatically communicate with each component and issue commands in a way that was intuitive and convenient. We needed to expose these methods to our end users so that they could manage and create workspaces without having to rely purely on the command line or interfaces established by AWS (i.e., Console or CLI). To achieve these goals, we began constructing a full-stack application that would eventually become the Armada application.
5.9.1 The Armada Application
Armada's backend is an Express application written in TypeScript which acts as the central control hub, connecting each component of provisioned architecture to ensure that instructors can provision and manage student workspaces at scale. The application itself is containerized and deployed within the group of containers known as the ECS Cluster, which provides guarantees about its health and availability.
5.9.2 The Software Development Kit (SDK)
In order to communicate with each piece of the architecture, we needed a structured interface with which to do so. Amazon offers a Software Development Kit (SDK) that provides a modular, class-based client for each resource that allows you to instantiate and send individual commands to perform common actions. Each command can be customized by defining properties on an `input` object. While performing each action in isolation is useful, Armada's needs continued to increase in complexity as its functionality was extended. By wrapping our feature set around the functionality defined within the SDK, the Armada team was able to encapsulate several isolated actions into singular endpoints, greatly simplifying an instructor's workflow.
For instance, when an instructor creates a workspace for a specific student, Armada performs the following actions under the hood using the SDK:
- Creates a task definition specific to the student, outlining the configuration of the requisite containers.
- Creates a target group for the student's workspace and attaches a rule to the listener on the ALB, allowing the workspace to receive traffic once it's operational.
- Creates a service specific to the student on ECS allowing its availability and health to be managed and monitored automatically.
- Stores information relevant to the creation and organization of data.
5.9.3 Instructors
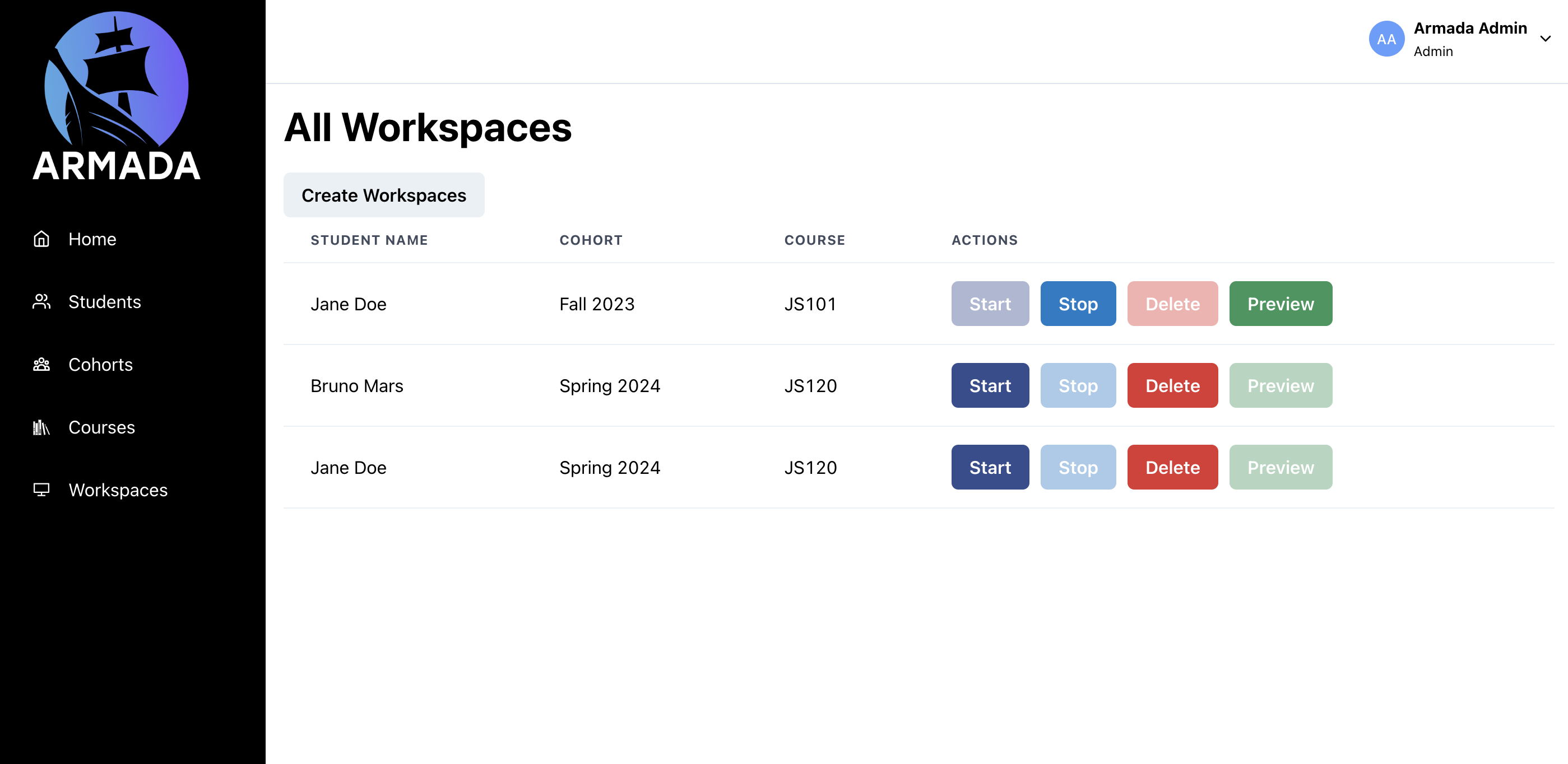
Within Armada, instructors are provided with several tools to create, organize, and manage their students' accounts and workspaces. Instructors can create individual accounts for students, group students into cohorts, and use those cohorts to enroll students into individual classes. Once a class has been populated, the instructor can generate individualized developer environments (i.e., workspaces) for every student. Each workspace is automatically associated with a given student and accessible through each student's student portal or through the instructor's "preview" button.
In addition, if an administrator needs to ensure that a student has the most up-to-date docker image for a given workspace, all they need to do is start and stop the service. ECS is automatically configured to retrieve the latest image when a container is created.
5.9.4 Students
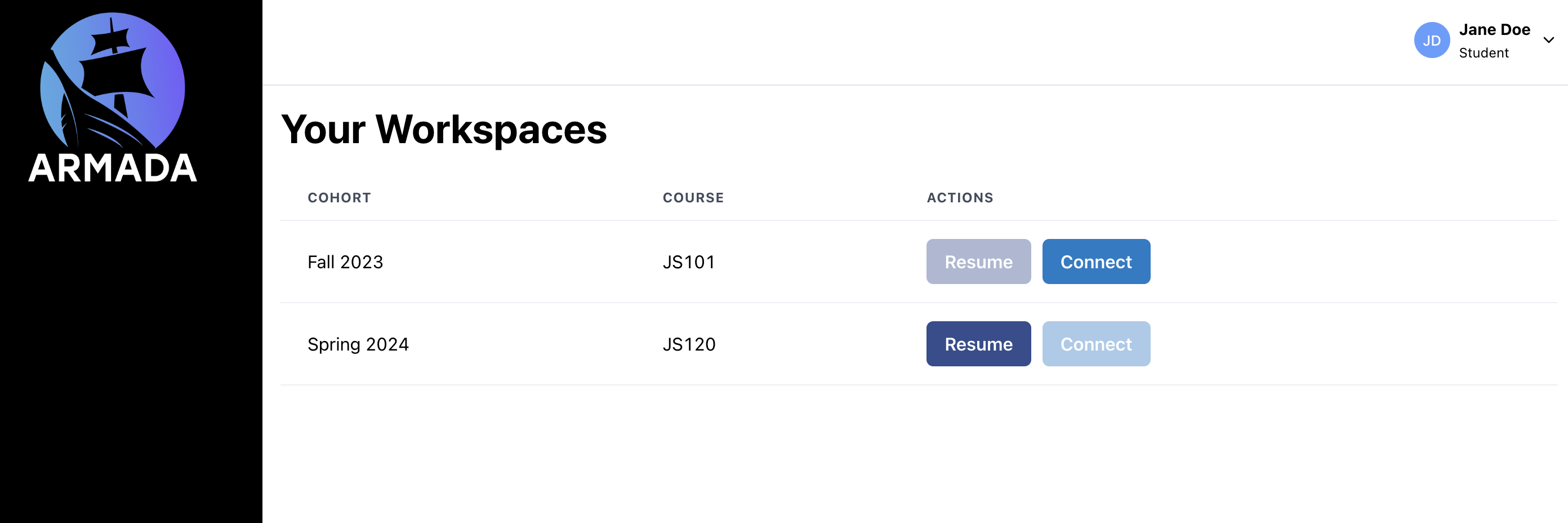
Armada provides a platform for students to access their workspaces. If a student's workspace is in an inactive state or has not yet entered a "running" state, the student can resume their workspace without instructor intervention. Most importantly, the student can connect to each of their workspaces and access all of their files.
5.9.5 A Step Above
By utilizing the SDK and offering a user interface, we gained programmatic access to each of our provisioned resources and created a layer of abstraction on top of AWS that makes it easy for both instructors and students to manage and access workspaces. For our application to work, however, we need the ability to establish and retain relationships between the individual pieces of our data, allowing for organization and clarity.
5.9.6 Establishing Relationships
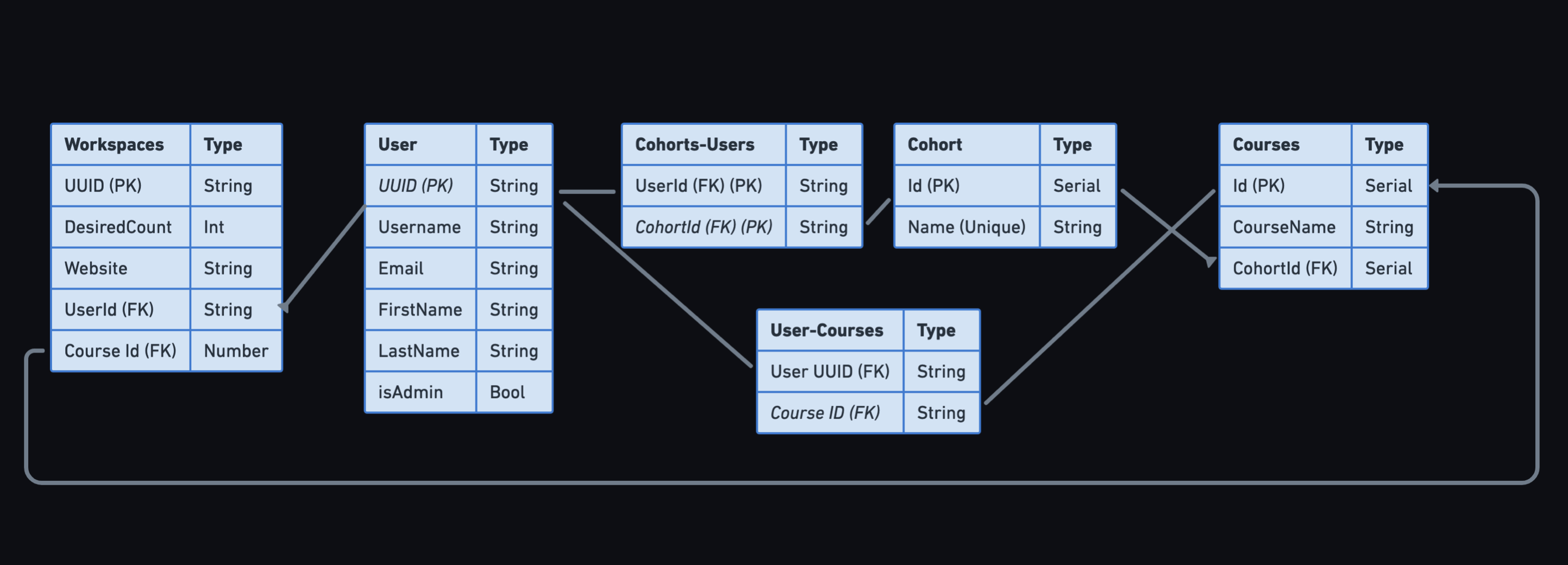
Before we could begin serving Armada to instructors or workspaces to students, we needed a database within our architecture that would help us manage the relationships between workspaces, students, courses, and cohorts (the term we use for students grouped together by an instructor).
To Host or Not to Host
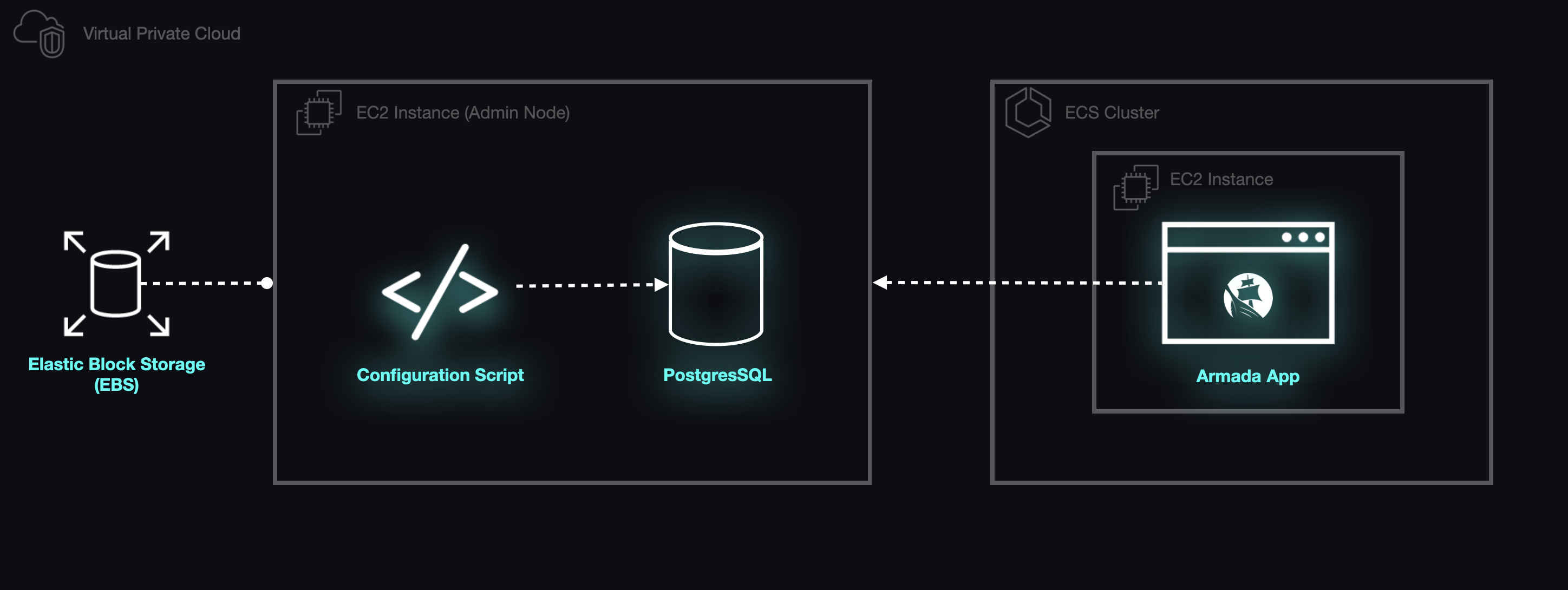
We initially considered implementing an instance of PostgreSQL, either on the server that would act as the host for Armada's backend or on a separate server intended solely to act as the host for the database. We quickly dismissed the former solution as we felt that it would be too fragile. Having decided that the database should be implemented on its own server, we then began to consider the possibility of using Amazon's managed solution, the Relational Database Service (RDS).
In some respects, provisioning a single EC2 instance to run PostgreSQL would have greatly simplified Armada's configuration. Had Armada been configured in this manner, it would have been trivial for the backend application to connect to the database and begin making queries. The only component that would need to be created would be a security group that allowed the backend application to communicate with the database host.
However, there were significant tradeoffs inherent in this approach. If this approach were selected, Armada would have been solely responsible for managing the database. Additionally, EC2 instances have ephemeral storage, and therefore, Armada would need to implement a mechanism for regularly backing up the database as well as methods to handle scenarios where the database crashed.
Relational Database Service (RDS)
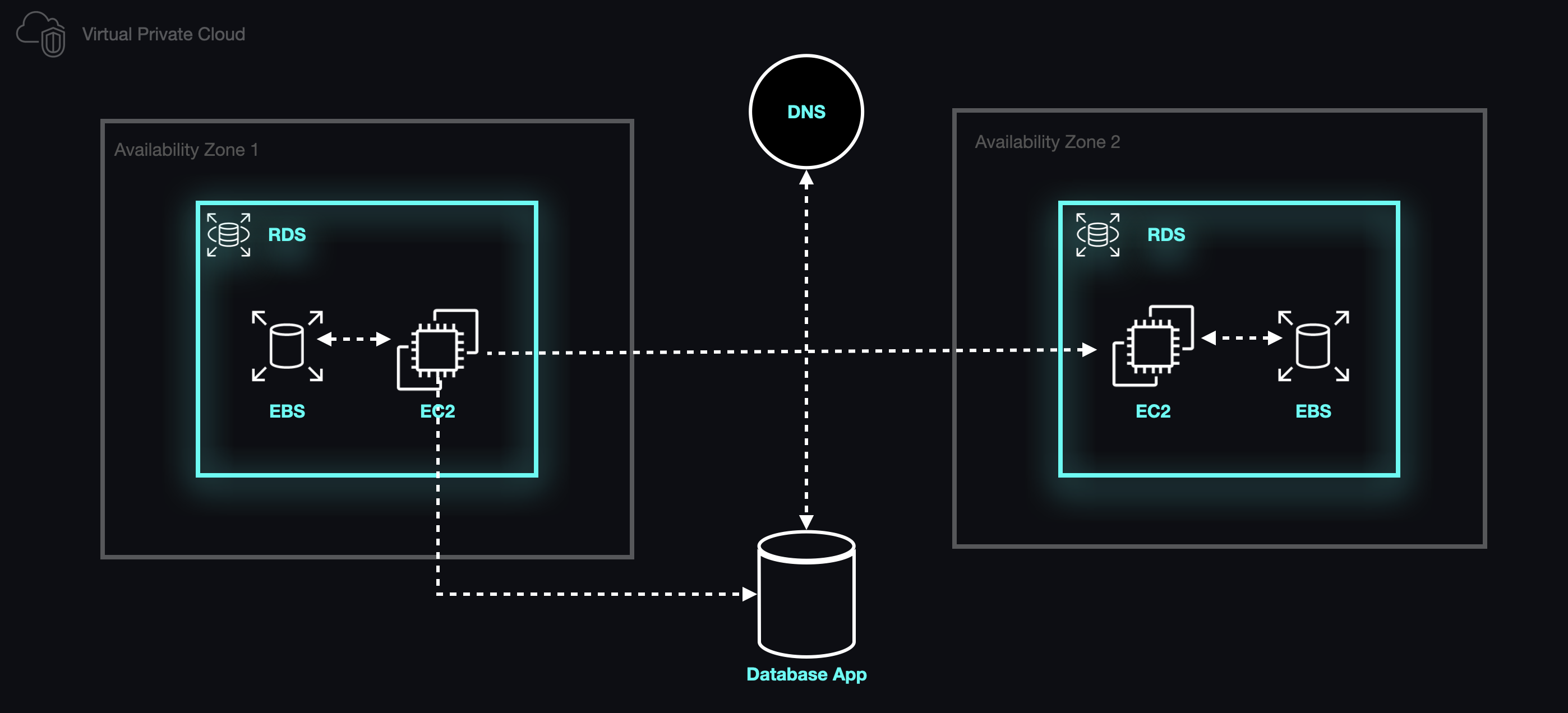
We decided that the cost of using RDS was low enough to justify using a managed service, as it traded ease of setup for a more resilient system in production. Our data would be automatically backed up and, in the event of a crash, RDS would automatically provision a replacement for our app.
Configuring the RDS instance to be accessible to the EC2 host for the backend app only required us to use a naming convention for those two resources in the CDK that automatically associated the database with the backend app's server. At this point we had a free-standing database that could manage all of the data relevant to the relationships among our users and their resources.
The Admin Node
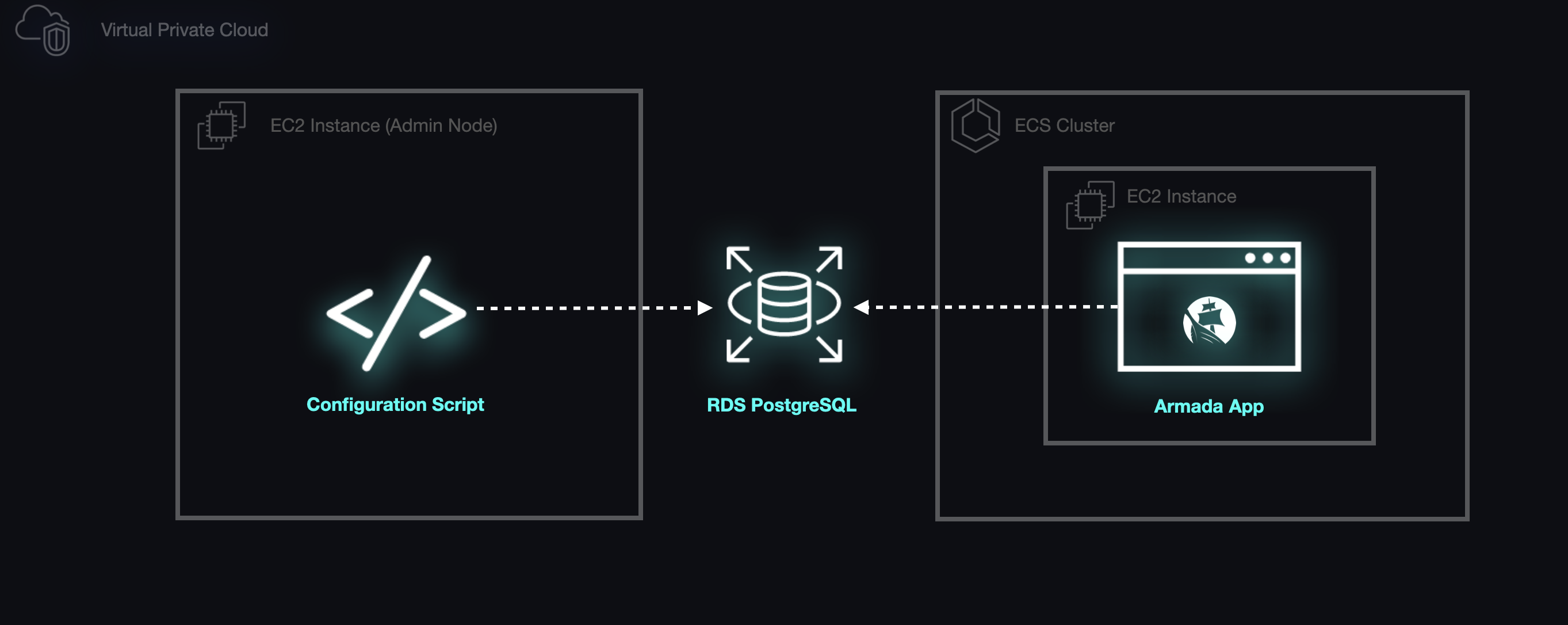
The final piece of the puzzle required us to be able to initialize the database schema. We accomplished this by adding an IAM role to the EC2 instance that would allow the host to retrieve data vital to establishing a connection to the database via the AWS CLI. We then wrote startup scripts to run as soon as the hosts for the backend app and database are provisioned, and after the backend app's host is able to connect to the database we use the PostgreSQL client to initialize our schema. At this point, Armada was ready to handle all requests from instructors and students.
Mischief Managed
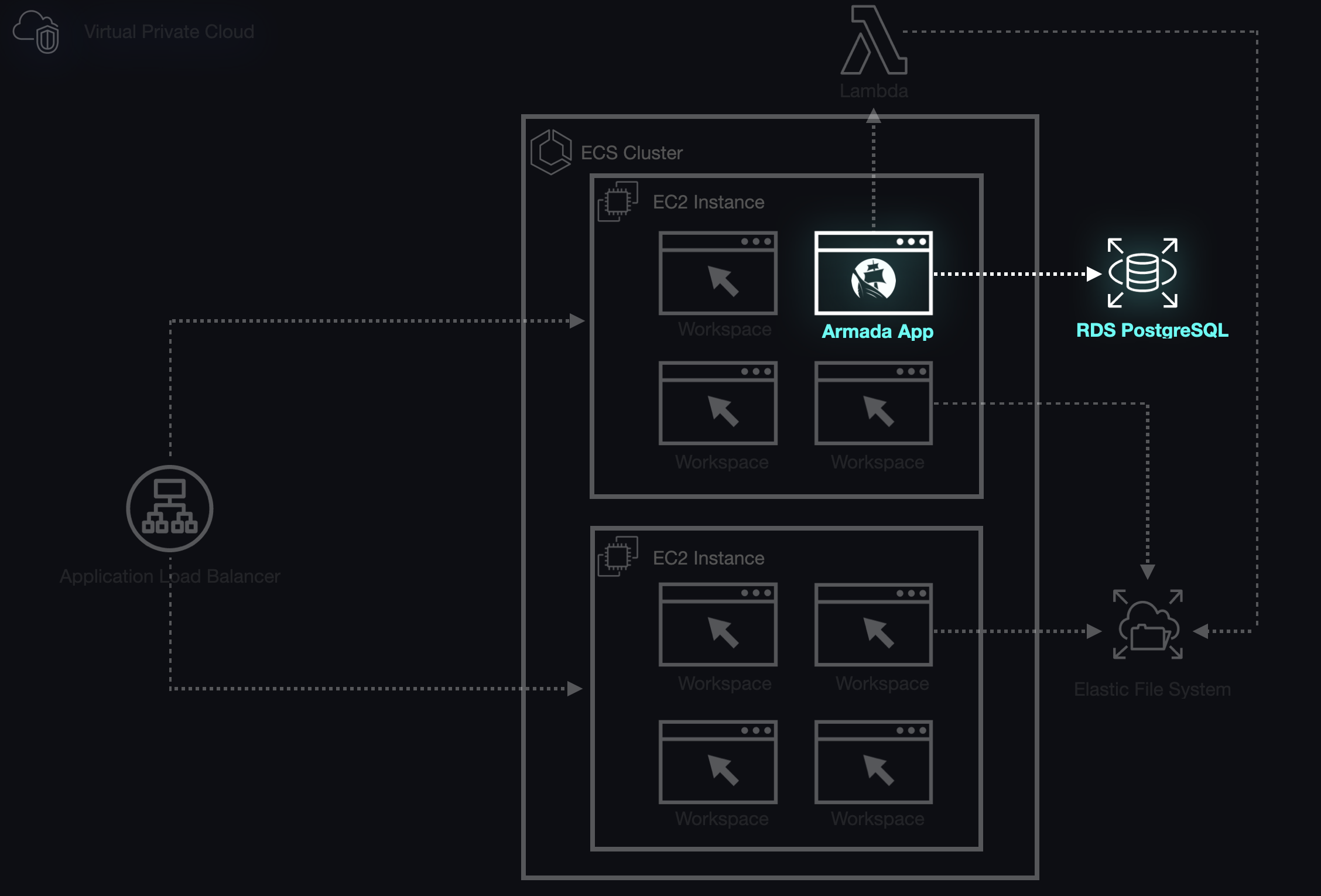
With the database in place and the admin node able to connect and make requests to that database, we had a way to efficiently manage relationships between all of the entities required to serve students' workspaces and allow instructors to manage students, workspaces, and cohorts. What the database did not explicitly give us the ability to do was differentiate between types of users on login, i.e. whether or not a given user should have administrative privileges.
5.10 Locking It Down
In order to offer differentiated access to our application we opted to create an authentication layer, which allowed us to direct users to the correct user interface on the app based on their role.
Authentication is notoriously a difficult area to develop due to the many issues around securely storing user credentials, warding off various types of attack by malicious actors, session management, and email and password retrieval. AWS has a managed solution for authentication with its Cognito service.
5.10.1 In Cognito
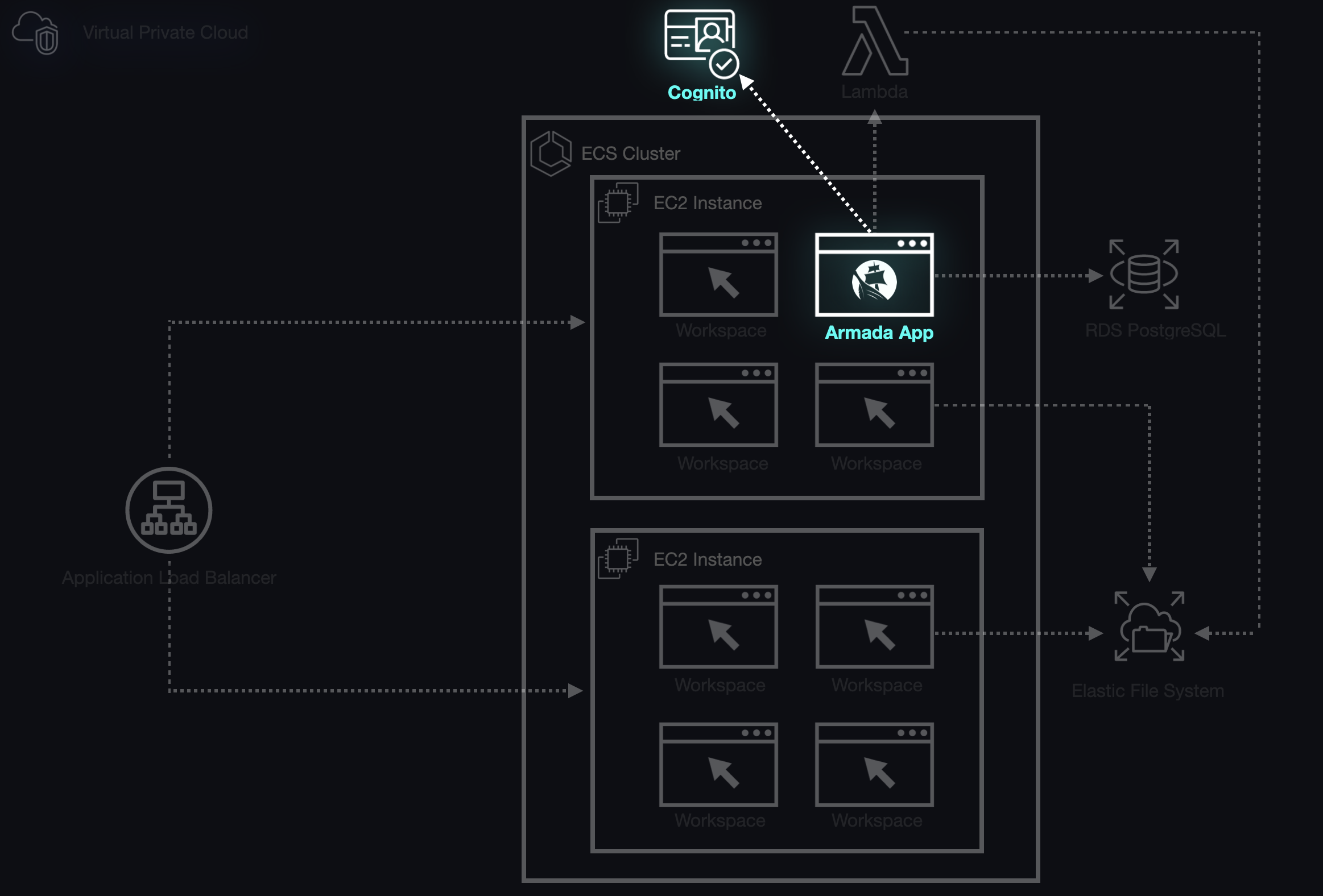
Cognito is a tool to connect applications to AWS and provides authentication, authorization, and user management through user and identity pools. We were able to use the CDK to provision a user pool and an admin user whenever the Armada infrastructure is first deployed. Then, when an instructor adds students through the Armada interface, this adds a user to the Cognito user pool along with their credentials, adds the student to the RDS database, and sends an email to that student with a temporary password. The student is then able to log in to see their designated workspaces. Although authentication was a small part of our application, it was critical to integrating some of the isolated pieces of the Armada application.
6. Our Goals Achieved
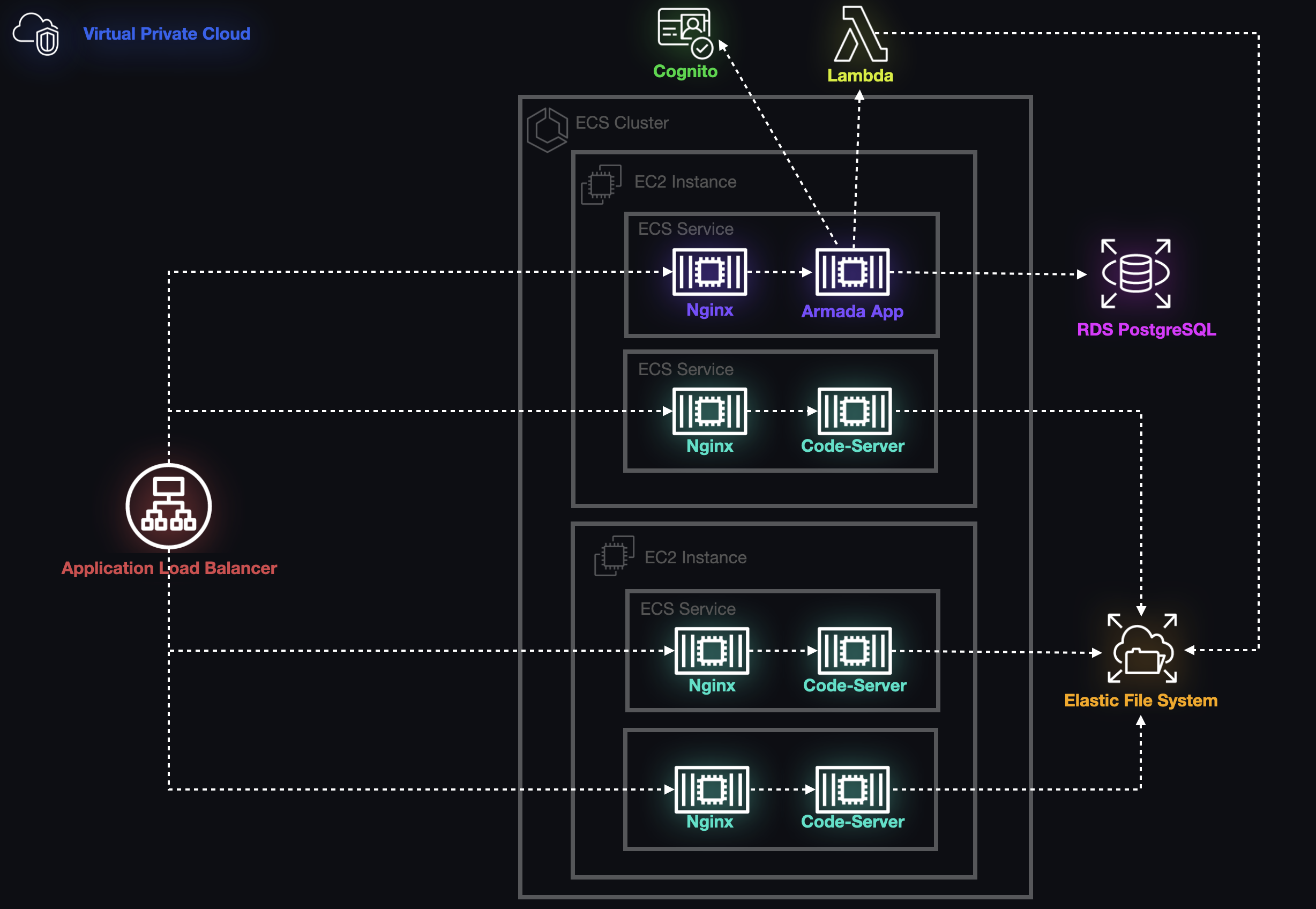
With authentication and the database in place, we had a way to associate users of all types with the resources that they might want to access in Armada. This associated data meant that we could use all of the other components of Armada to serve students their specific workspaces in the browser and allow them to keep track of their work without having to perform any configuration or installations on their own machines. Instructors can also create custom development environments to deploy to an arbitrary number of students without needing to directly interact with AWS. Additionally, Armada's optimizations ensure the lowest cost for instructors, maximizing efficiency while preserving usability.
7. Future work
In the future, we would like Armada to have extended features that allow instructors to specify custom development environments for their courses using their own Docker images. This would allow for the ultimate flexibility in creating workspaces that are catered to an exact course or situation. Other avenues for improvement include:
- Creating a one-click deployment for AWS via CloudFormation to make generating the infrastructure easier.
- Integrating with GitHub repositories to allow the data from the repository to be automatically inserted into the generated workspaces.
- Integrating existing solutions either via VS Code Live Share or paid extensions that allow users to work collaboratively within a single environment.
- Implementing cost-saving measures such as spinning down ECS Services when the containers are not in use.
8. Team



